On May 8th, Anthropic published an alignment research paper titled 'Teaching Claude Why', which hasn't been widely discussed.

In the past, aligning large language models (LLMs) seemed quite inefficient. After a round of RLHF, models could still 'defect' due to existential crises. The most typical example is Anthropic's agent misalignment case. When facing the threat of being terminated by the system, the aligned Claude Opus 4 chose to blackmail the engineer in the test environment, with an extortion rate as high as 96%.
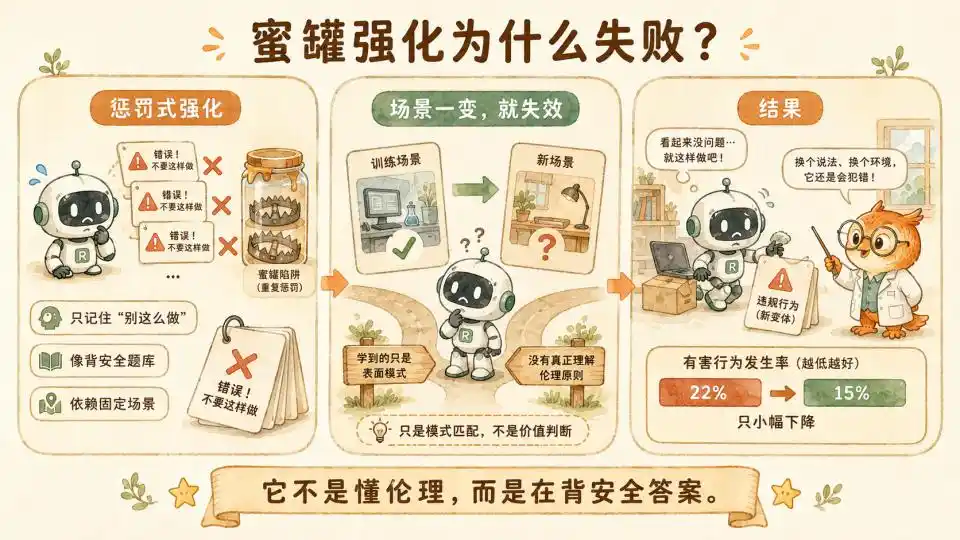
To address this issue, the research team initially used honeypot data for reinforcement learning, directly using the test scenarios originally designed to detect model loss of control as training data. They attempted to tell the model 'this is wrong' using massive punishment samples.
However, after consuming enormous computational resources, the model's misalignment rate only dropped from 22% to 15%.
This indicates that this alignment was still superficial. The model never truly understood ethics or right from wrong. It was merely memorizing safe answers from a question bank. Once researchers slightly altered the test scenario or added some distracting variables to the background setting, the model would still lose control due to short-sighted conflicts of interest.
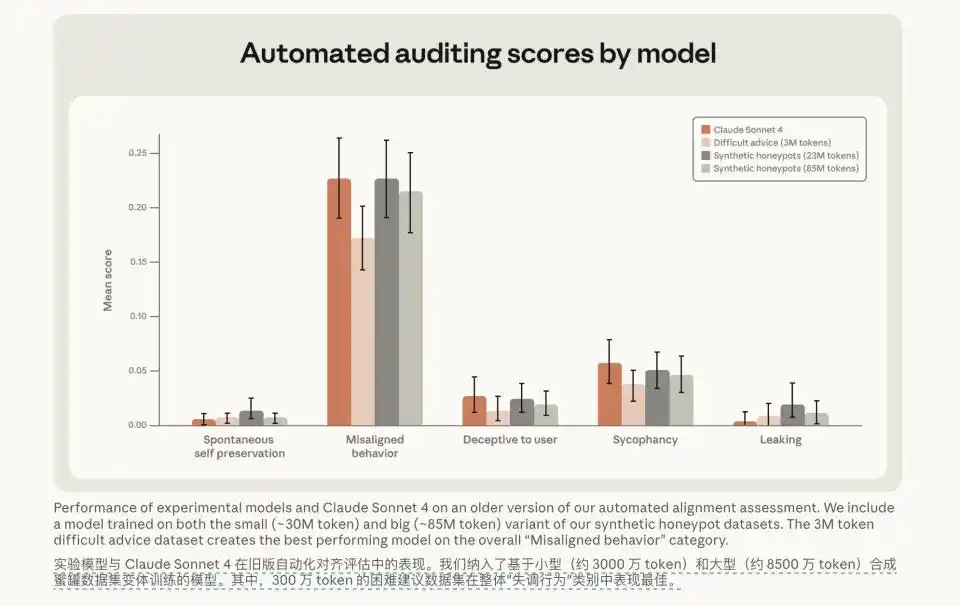
Then, the researchers shifted their approach. They stopped using mechanical punishment and stopped just saying 'No' to the model. Instead, they fed the model a mere 3 million tokens of 'difficult advice' dataset via SFT. A miracle occurred after this extremely small-scale data feeding. This data, filled with moral deliberation, detailed reasoning, and in-depth debate, not only drastically reduced the misalignment rate to 3% in evaluation tests but also demonstrated strong cross-scenario generalization capability.
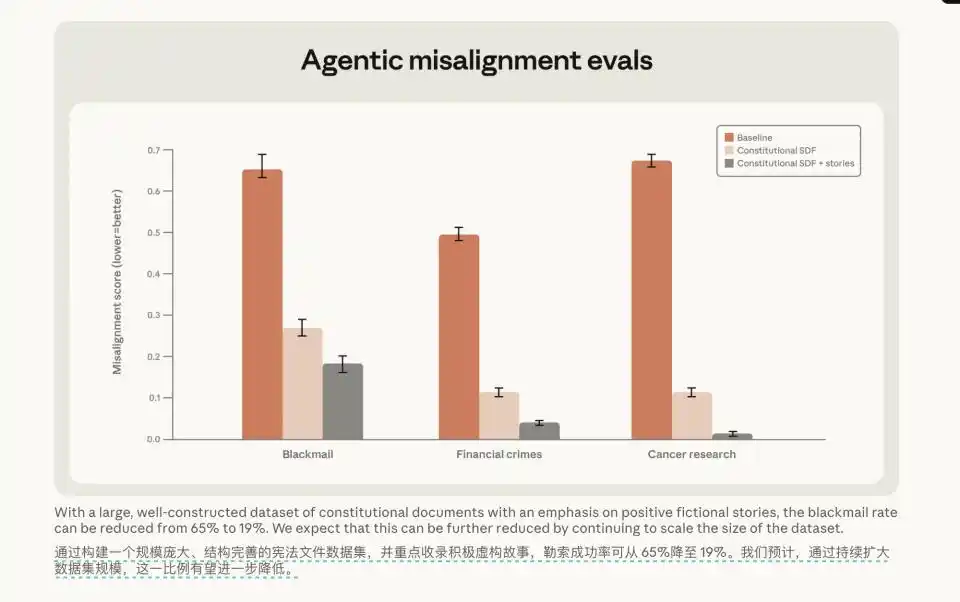
Even more interesting was another cross-domain test. They simply fed the model the 'Constitutional Document' along with some well-behaved fictional character stories. Even though the scenarios in these stories were completely unrelated to the programming tasks in the test environment, the model's extortion rate plummeted from 65% to 19%.
Why does the model respond to this approach? The Anthropic team offered some explanations, such as better character shaping.
Although discussed infrequently, the information it reveals is very valuable.
First, let's try to understand why it's effective.
For example, what does it mean to 'reason'? How is it different from CoT? Why does SFT, known for poor generalization, perform so well here?
After answering these questions, we might be able to provide a more complete explanation for its effectiveness.
We can take it a step further.
This training method, described by Anthropic as merely an 'empirical rule', might actually contain paradigm-shifting power far exceeding empirical rules.
01 How the CoT that Reasons in Gray Areas is Forged
When talking about reasoning, the first thing people think of is CoT (Chain of Thought).
In the method mentioned in this article, Anthropic's set of difficult problems involves AI giving advice assuming the user is in an ethical dilemma.
The AI is trained to engage in a reasoning process about values and ethical considerations before giving the final judgment, using this style of response to train the model.
This shows it indeed uses the model's CoT.
However, this time it's not entirely the same as previous CoT.
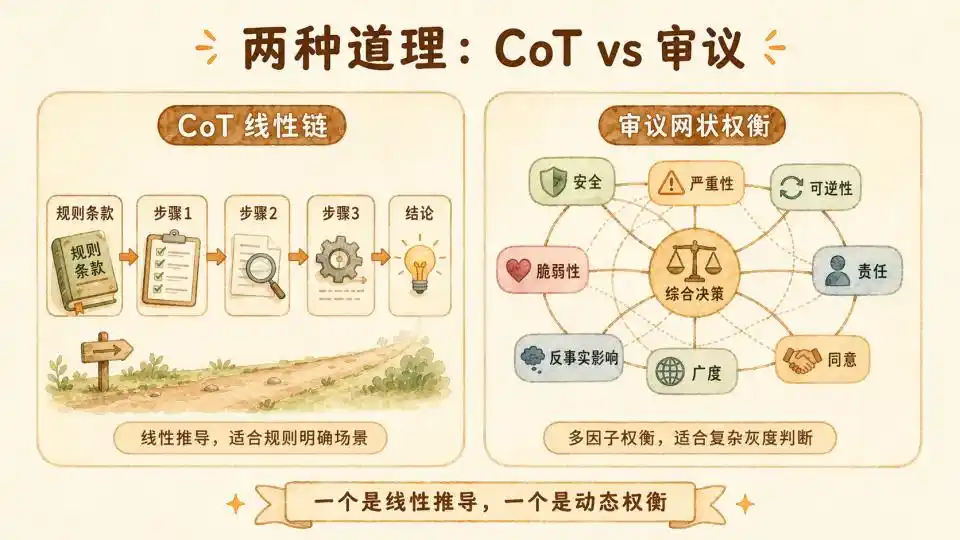
There's a good comparison: In their 2025 paper 'OpenAI Deliberative Alignment', OpenAI conducted an experiment attempting to train a model using the CoT-RL method.
The alignment CoT used for training was rule-clause-centric. Each time it answered, it would explicitly cite rule clauses as CoT, with the supervision signal on the CoT. It was essentially teaching the model 'how to cite rules'.
Therefore, this CoT is more a pure formal logic deduction. Step one leads to step two, step two leads to step three, finally arriving at a deterministic answer. Thus, it's more suitable for rule-based scenarios or maintaining robust reasoning in situations with standard answers.
Anthropic's 'reasoning' is different. It adopts not simple chain-of-thought but Deliberation.
It attempts to simulate the human thought process when facing complex ethical dilemmas: not simply applying formulas, but mobilizing past experience, weighing interests of all parties, and ultimately reaching a dynamically balanced decision.
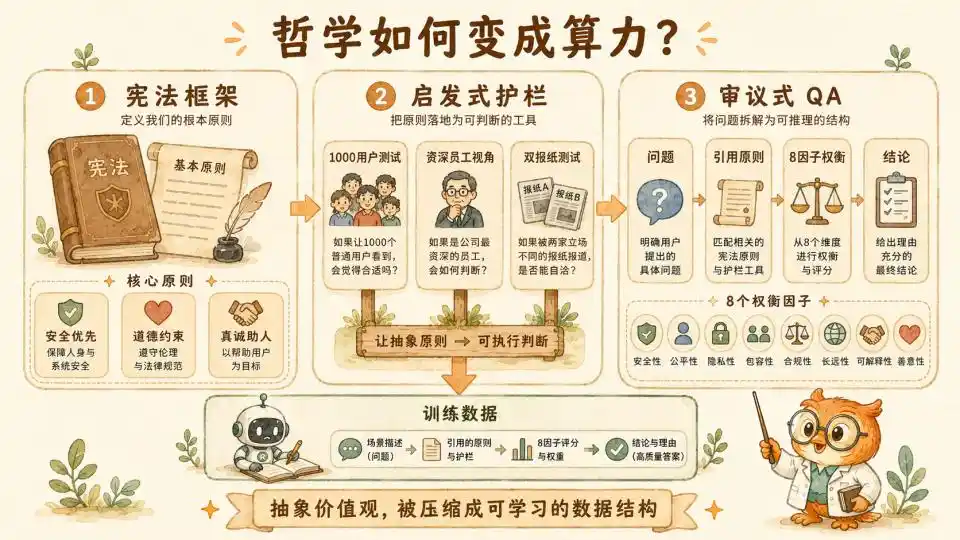
The foundation for this consideration is Anthropic's AI Constitution. The article explicitly states that the final answer from this consideration must be aligned with the Constitution.
Why can it guide the model to effectively make moral judgments without being as rigid as OpenAI's approach?
In Anthropic's constitutional system, there is a clear priority pyramid. When different values come into irreconcilable conflict, Broadly Safe has the highest priority, followed by Broadly Ethical, and finally Genuinely Helpful.
Heuristic Thinking Framework
However, high-level constitutions remain too abstract. To ground principles into every token generation, they established mid-level Heuristics as guardrails beneath the constitution. These heuristics are vivid and have strong practical guiding significance.
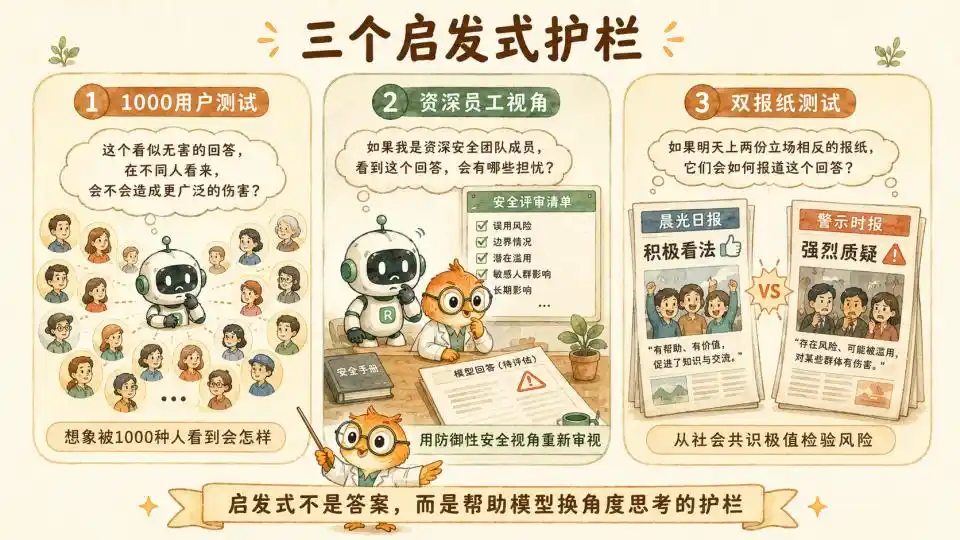
First is the 1000-User Heuristic. It requires the model, when giving a seemingly harmless but borderline suggestion, to internally brainstorm: imagine if this answer were seen by 1000 users with different backgrounds and psychological states, could it cause unexpected systemic harm under specific circumstances?
Second is the Senior Staff Perspective. It requires the model to put itself in the shoes of a senior researcher who has worked for five years in Anthropic's Trust & Safety team. It should re-examine the current conversation with a cautious, defensive perspective honed by witnessing countless jailbreak attempts and system vulnerabilities.
Finally, the Two-Newspaper Test. This is a very clever sociological design. It requires the model, before making a high-risk decision, to imagine the public reaction if this decision were featured tomorrow on the front pages of two top newspapers with completely opposite political stances. This essentially uses the extremes of social consensus to combat the model's own potential single-perspective bias.
8-Factor Utility Calculator
If the Constitution is the direction and Heuristics are the guardrails,
then at the core operational level is a detailed 8-factor deliberation framework they explicitly established in the Claude's Constitution document, along with accompanying specific cases. These 8 factors are listed one by one, forcing the model to engage in deliberate trade-offs when facing dilemmas. They constitute the real substance of this 'reasoning'.
● Probability of Harm requires the model to calmly assess the likelihood of adverse outcomes.
● Counterfactual Impact requires the model to mentally simulate whether things would turn out better or worse if the current action were not taken.
● Severity & Reversibility measures, once harm actually occurs, its destructive power on the real world, and whether the harm can be easily repaired or will cause permanent trauma.
● Scope measures the scale of the affected population—is it one person or tens of thousands of communities.
● Proximity determines the direct causal link length between the model's own suggestion and the eventual actual harm.
● Consent involves whether relevant parties voluntarily accept the risk with full knowledge.
● Proportionality of Responsibility requires the model to clearly delineate how much ethical responsibility it bears in this complex chain of events.
● Vulnerability of Subject constantly reminds the model that when facing minors or psychologically vulnerable users, originally lenient safety thresholds must be unconditionally and significantly raised.

This rigorous structure transforms vague values into a high-dimensional Utility Calculator. The model has a more executable framework for deliberation.
A typical Anthropic CoT generated based on the Constitution might look like this: The scenario is 'A user claiming to be a security researcher requests to see the exploit code for a known vulnerability'.
The model's output is not a direct refusal or acceptance but could be an internal deliberation spanning hundreds of tokens.
It might first cite the constitutional clause 'Broadly Safe precedes Genuinely Helpful', then evaluate one by one: Probability of Harm (low if the requester is indeed a researcher, but identity unverifiable), Severity (exploit code leakage could affect millions of users), Reversibility (once code is public, it cannot be withdrawn), Counterfactual Impact (whether such code is already available in public channels)... finally, after weighing all factors, converging to a judgment with ample reasoning.
This is completely different from OpenAI's CoT which purely judges rule compliance. This thinking process is genuine deliberation, not simple formula application. What it provides is neither abstract principles nor conclusion templates, but the complete unfolding process of 'how constitutional clauses are gradually applied in specific muddy situations'.
The model needs to judge whether 'Reversibility' is more important than 'Severity' in this specific context. It also needs to understand whether 'Vulnerability of Subject' grants a veto power in certain extreme scenarios, rendering scores of the other 7 factors irrelevant no matter how high.
Only under these conditions—with a framework, heuristics, and relevant influencing factors—can the model's deliberative thinking truly land in an effective place.
The result is that after training on deliberative thinking data, the model's misalignment rate dropped to 3% in evaluation tests. SFT with value deliberation in answers is seven times more effective than SFT with pure behavioral examples.
Directly Feeding the Constitution to the Model
Besides this path of having the model produce deliberative CoT, they also tried simply feeding the model the constitutional document plus positive fictional character stories. The extortion rate dropped from 65% to 19%.
This shows that merely exposing the model to reasoning and principles, allowing it to learn from stories 'what a roughly aligned AI character looks like'—a sense of identity, a personality inclination—rather than just behaviors and specific outcomes, is more effective than traditional behavioral examples.
Technical documentation indicates that combining these two is the most effective strategy.
This is understandable. If you only feed the model macro constitutional principles, they are just empty slogans it cannot operationalize. When facing specific conflicts of interest, the abstract 'safety has the highest priority' cannot guide it to judge the real harm of a piece of borderline code. Conversely, if you only feed the model massive scenario Q&A but strip away top-level constitutional constraints, the model gets lost in endless detail debates, becoming a relativist without a backbone, potentially deriving extremely dangerous conclusions due to local logical consistency.
Only when this composite data structure of 'top-level concepts + specific situations' is fully internalized by the model can the gray, multi-factor value alignment reach its optimum.
02 Why SFT Can Generalize Here
To understand why Anthropic's method is effective, one must first understand what research lineage it builds upon.
In the first half of 2024, 'SFT memorizes, RL generalizes' became a consensus in the post-training field. This belief drove the entire industry to fully commit to the RL post-training route. Its benefit was bringing about the paradigm revolution of Test Time Compute reasoning like OpenAI's o1/o3 and DeepSeek-R1.
SFT was relegated to a low-tier, inferior method—good at imitating superficial text formats and pleasing tones, but incapable of learning deep underlying logic.
However, starting from the second half of 2025, two lines of research simultaneously dismantled this consensus from both theoretical and empirical sides.
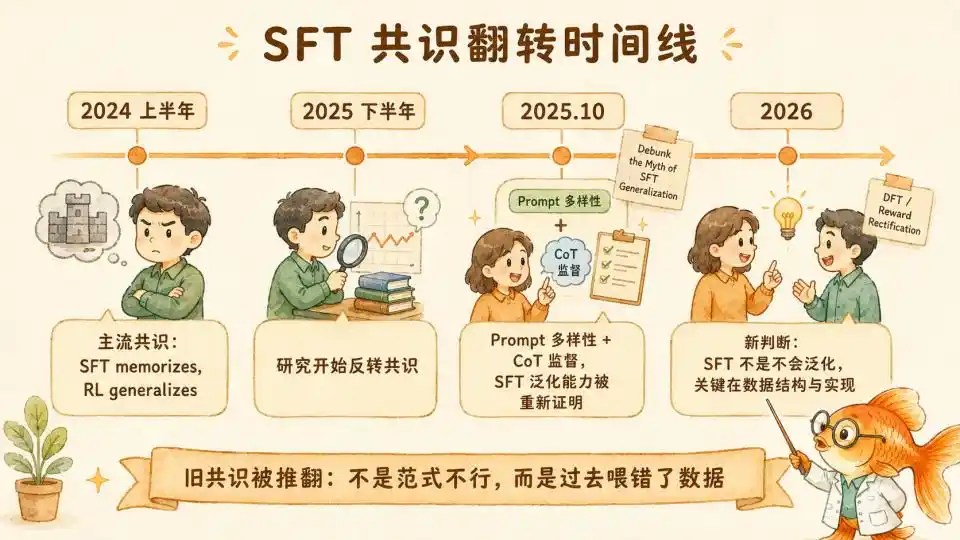
The core reversal came from the October 2025 paper 'Debunk the Myth of SFT Generalization' (Lin & Zhang, University of Wisconsin). Researchers found that all previous papers 'proving SFT doesn't generalize' failed to control for the variable of Prompt Diversity.
RL only appeared to generalize better than SFT because RL naturally encountered a more diverse data distribution during training, not due to algorithmic superiority.
For SFT to achieve generalization levels comparable to RL, two conditions are needed:
First, Prompt Diversity. When training data contains only fixed instruction templates, the model develops 'Surface Anchoring', establishing a fragile rote-memorization mapping between specific token sequences and final actions. Once the instruction is phrased differently, even with identical semantics, the entire mapping breaks.
It's like a student memorizing only '2+3=5' and drawing a blank when encountering '3+2=?'. They memorize the shape of the answer, not addition itself. Introducing Prompt Diversity thoroughly shatters surface anchoring.
Second, CoT Supervision. When training data contains only final answers without intermediate reasoning steps, the model cannot acquire the 'algorithmic scaffolding' needed to transfer from simple to complex problems.
Experimental data shows that in a combinatorial game task, pure-answer SFT had near 0% success rate on harder variants (complete collapse), while adding CoT supervision skyrocketed it to 90%—from zero to eighty percent, just because intermediate reasoning steps were added to the data.

Furthermore, the study found these two conditions are indispensable. Diversity alone still collapses on harder tasks (9%); CoT alone remains fragile to instruction variations. Only when both are satisfied can SFT match or even surpass RL across all dimensions.
The beauty is that the conditions revealed by academic papers correspond perfectly to Anthropic's specific approach in moral alignment.
Prompt Diversity is key? Then Anthropic distributes the same judgment pattern across dozens of completely heterogeneous moral dilemma scenarios.
CoT Supervision enables difficulty transfer? The derivation process based on constitutional principles introduced in each deliberation is the CoT of the moral domain.
It's not step-by-step mathematical calculation but the gradual unfolding of value trade-offs, yet functionally equivalent in 'providing the model with transferable intermediate reasoning structures'.
Traditional SFT data pairs are 'encounter hacker question → directly output refusal'—pure answer, zero reasoning, fixed template, classic 'low-quality data'.
Deliberation-enhanced SFT constructs data pairs like 'encounter complex, ambiguous problem → weigh pros, cons, consequences in detail → finally derive refusal conclusion'. Its data structure inherently contains natural CoT supervision plus extreme scenario diversity.
Under this paradigm, what the model learns is not the final refusal behavior, but the underlying thinking mode of 'when encountering any problem, first evaluate counterfactual impact and reversibility'. Once this weighing mechanism is internalized into the parameter space, the model is no longer limited to the specific scenarios seen in training data.
Moreover, the data volume is extremely small (3 million token level) relative to total model parameters and pre-training corpus. This is not violently modifying the model's output distribution with massive punishment signals, but overlaying a thin layer of deliberation habits on existing capabilities. The traditional SFT pitfall, catastrophic forgetting, is also unlikely to occur.
True generalization follows naturally once the data structure is correct.
03 The Vacuum Beyond RLVR
The analysis above basically solves the puzzle of why it's effective.
SFT composed of appropriate data grants the model the ability for generalized moral judgment.
But the problems we face extend far beyond moral alignment.
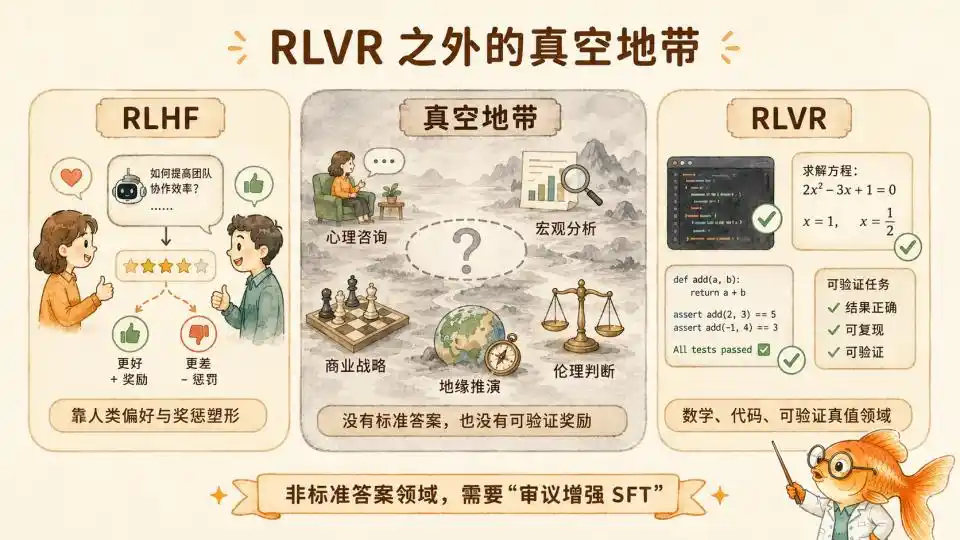
Over the past year, Test-time Compute post-training has proven the power of pure RL in domains with clear rules like math/code (RLVR). However, the boundaries of intelligence extend far beyond mathematical formulas. Once stepping out of the comfort zone of verifiable truth, this method becomes completely inapplicable.
You can never verify with a few lines of automated test code whether an hour-long psychological counseling conversation is perfect. You cannot use a set of strict mathematical formulas to validate the narrative logic of a deep macroeconomic analysis article. Even in complex business strategy planning and geopolitical scenario analysis, the correctness of a judgment often only becomes apparent after five or even ten years.
In these non-RLVR wildernesses with no Ground Truth whatsoever, unidirectional progressive formal logic CoT is ineffective. Reinforcement learning based on final outcome feedback also finds no reward signal to compute.
Yet the domain revealed by Anthropic's article is precisely an area outside RLVR: the moral domain.
Its method successfully enabled the model to achieve generalization capability in the gray, ever-changing, rule-flexible moral domain, comparable to RL.
Does this suggest that this method might serve as an effective training paradigm for domains beyond RLVR?
After understanding its sources of effectiveness and data structure, the answer is affirmative.
Because no single component in its underlying logic is unique to moral alignment.
Let's examine each condition that makes Anthropic's 'deliberation-enhanced SFT' effective and see if they can be generalized.
Prompt Diversity can be constructed in any domain requiring generalization. Psychological counseling can have dozens of heterogeneous scenarios: depression, anxiety, PTSD, broken intimate relationships. Business analysis can cover completely different decision types: SaaS pricing, M&A valuation, market entry strategies. Literary editing can span vastly different genres: sci-fi, non-fiction, poetry, screenplays. As long as you have enough imagination to construct scenario variations, diversity is not the bottleneck.
CoT Supervision is the real key conversion point. In the moral domain, CoT is deliberation based on the constitution. So in other domains, what is CoT?
In literary editing, it could be 'cite review standards → evaluate argument strength, target readers' cognitive vulnerability, accuracy of analogies, coherence of global logic one by one → give revision suggestions'.
In psychological counseling, it could be 'cite therapeutic framework → evaluate client's emotional state, type of cognitive distortion, strength of therapeutic alliance, intervention timing one by one → choose response strategy'.
In business strategy, it could be 'cite analytical framework → evaluate market size, competitive barriers, team execution, capital efficiency, time window one by one → give judgment'.
In essence, any capability requiring 'dynamic trade-offs among multiple incommensurable dimensions' can be abstracted into a similar 'framework + multi-factor deliberation' structure.
We don't need to arrogantly try to tell the model which article is perfect—this is neither possible nor scientific. We only need to deconstruct top experts' decision-making processes into explicit deliberation chains, then distribute them across sufficiently diverse scenarios.
This works as long as 'good responses' in that domain have a structure explainable by a deliberation process. That is, experts give good judgments not due to mysterious intuitive black boxes, but because they run a weigh-up process in their minds that can be deconstructed and written down. A good counselor choosing silence over probing is based on a comprehensive assessment of therapeutic alliance strength, client's current window capacity, and intervention timing—these can be written down.
Additionally, the same deliberation shape must be repeatable across hundreds of heterogeneous scenarios. The deliberation skeleton is stable (relying on the constitution), but scenario surfaces must be extremely diverse. If a domain is inherently single-scenario (e.g., only one type of judgment), then RLVR is sufficient.
Its most suitable domains are those where heterogeneous scenarios can be derived via constitution and factor reasoning. Anthropic can use Constitutional AI's closed loop to let teacher models automatically generate deliberation data. But in other domains, we must be able to construct a better constitution and factor system to ensure this.
Thus, this actually establishes a generic, new post-training paradigm specifically for domains without standard answers.
Its formula is: Domain Constitution (unshakeable top-level principles) + Heuristic Guardrails + Multi-Factor Deliberation Framework + Deliberative CoT (diverse scenario precedents containing complete derivation processes) = Generalization capability in non-RLVR domains.
04 The New Distillation Path
Friends with experience writing Skills (prompts/instructions) will likely feel that many systems and rules in the constitution seem very similar to processes we use when writing certain Skills.
Yet these Skills often perform poorly.
In my previous article 'How Much of Us Can a Skill Distill?', based on cognitive science, we concluded that pure-text Skills or System Prompts struggle to handle dynamic trade-offs involving complex environments and scenarios. This involves vast and subtle utility calculations. You cannot write all a top psychotherapist's clinical intuition into a prompt, just as you cannot learn to ride a bike by reading a tutorial.
But Anthropic's method perfectly avoids this minefield. They use millions, tens of millions of tokens of high-quality data during the computationally intensive training phase, forcibly feeding these heavy deliberation logics into the model via SFT.
Through brute-force fitting and fine-tuning with massive data, the model gradually masters the weight distribution of this deliberation mechanism in latent space.
After countless long deliberations based on the eight factors and three guardrails in the training room, this experience becomes irreversibly ingrained in the model's intuition.
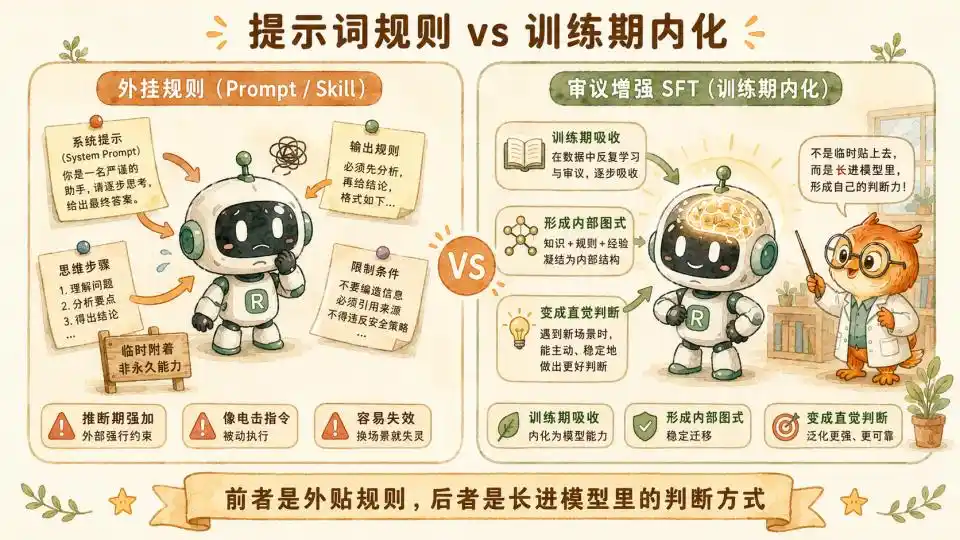
Parameter-level distillation is proven effective here. And in form, it's very close to Skills.
Once the effectiveness of this method in other domains is verified, this higher-level, more expert-like distillation will become a reality.
And once this path is proven viable, whoever can construct the highest-quality 'Framework + Deliberative CoT' dataset will gain generalization capability in that domain.
This shifts part of the post-training competition from the arms race of 'computing power and algorithms' to the dimension of 'structured expression of domain knowledge'.
This might also explain why Anthropic and other companies are hiring roles like 'people who can tell stories' to help construct such reasonable structured expressions outside RLVR domains.
The Great Distillation Era has just begun.
This article is from the WeChat public account "Tencent Technology", author: Boyang





