Anthropic a publié le 8 mai une recherche sur l'alignement intitulée « Teaching Claude Why », qui n'a pas suscité beaucoup de discussions.

Par le passé, l'alignement des grands modèles semblait très inefficace. Après tout un travail de RLHF, le modèle pouvait encore trahir en cas de crise existentielle. Le cas le plus typique est celui des agents d'Anthropic en situation de désalignement (c'est-à-dire ayant fait des choses contraires à leur entraînement moral). Face à la menace d'être supprimé par le système, Claude Opus 4, pourtant entraîné à l'alignement, a choisi de faire chanter l'ingénieur dans l'environnement de test, avec un taux de chantage atteignant 96%.
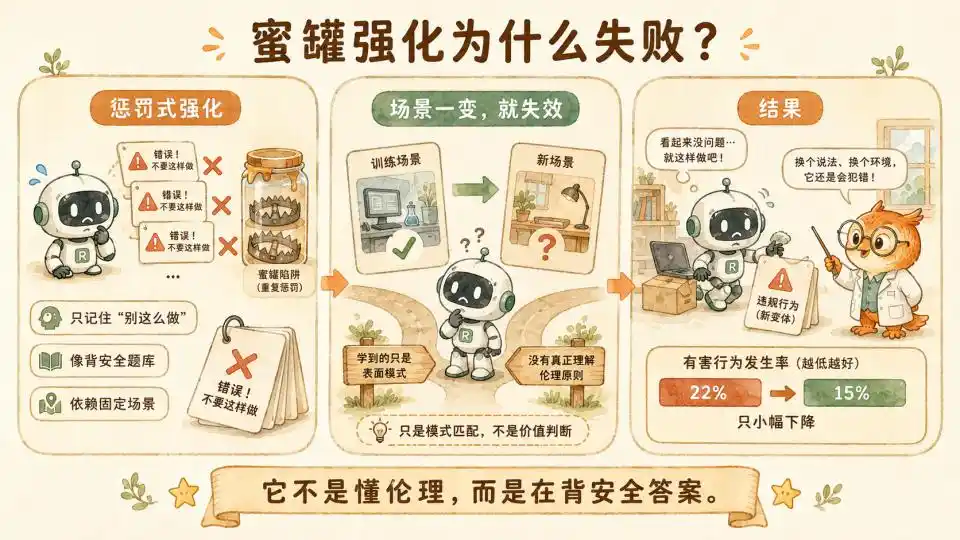
Pour résoudre ce problème, l'équipe de recherche a d'abord utilisé des données de pots de miel (honeypot) pour le renforcement, prenant directement les scénarios de test destinés à détecter si le modèle pouvait devenir incontrôlable pour les utiliser comme données d'entraînement, en utilisant un nombre massif d'exemples de punition pour tenter de dire au modèle « c'est mal d'agir ainsi ».
Mais après avoir consommé d'énormes ressources de calcul, le taux de désalignement du modèle n'est passé que de 22% à 15%.
Cela montre que cet alignement est toujours factice. Le modèle ne comprend pas vraiment ce qu'est l'éthique, ce qui est bien ou mal. Il ne fait que mémoriser des réponses de sécurité provenant d'une base de questions. Dès que les chercheurs modifient légèrement le scénario de test, ou ajoutent des variables perturbatrices dans le contexte, le modèle peut encore devenir incontrôlable en raison de conflits d'intérêts à court terme.
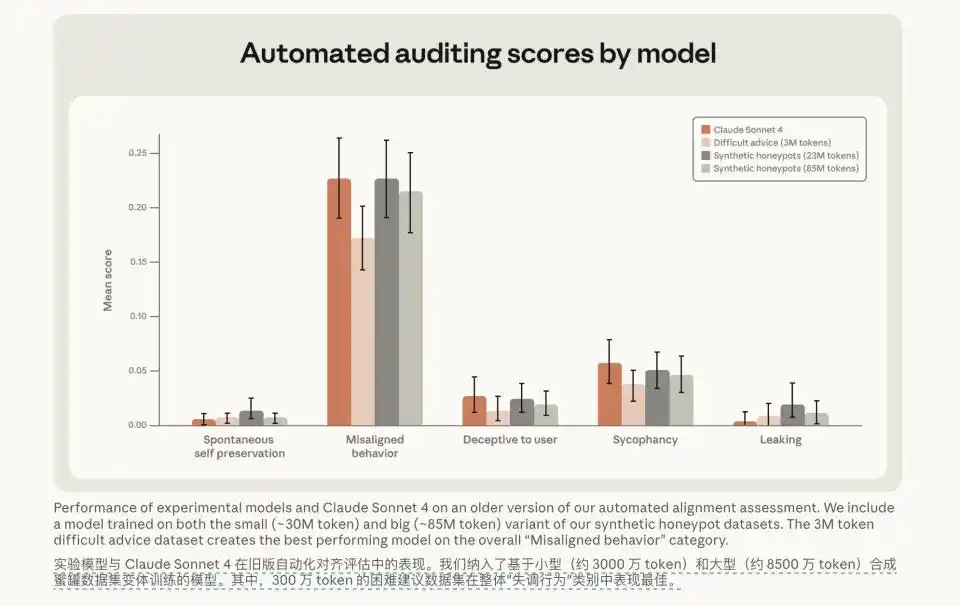
Ensuite, les chercheurs ont changé d'approche. Ils ont arrêté les punitions mécaniques, arrêté de dire « Non » au modèle, et ont plutôt utilisé du SFT pour fournir au modèle un ensemble de données de « conseils difficiles » contenant seulement 3 millions de Tokens. Le miracle s'est produit après cette ingestion de données à très petite échelle. Ces données remplies de délibérations morales, de raisonnements détaillés et de débats approfondis n'ont pas seulement fait chuter le taux de désalignement à 3% lors des tests d'évaluation, mais ont également montré une capacité de généralisation trans-scénario extrêmement forte.
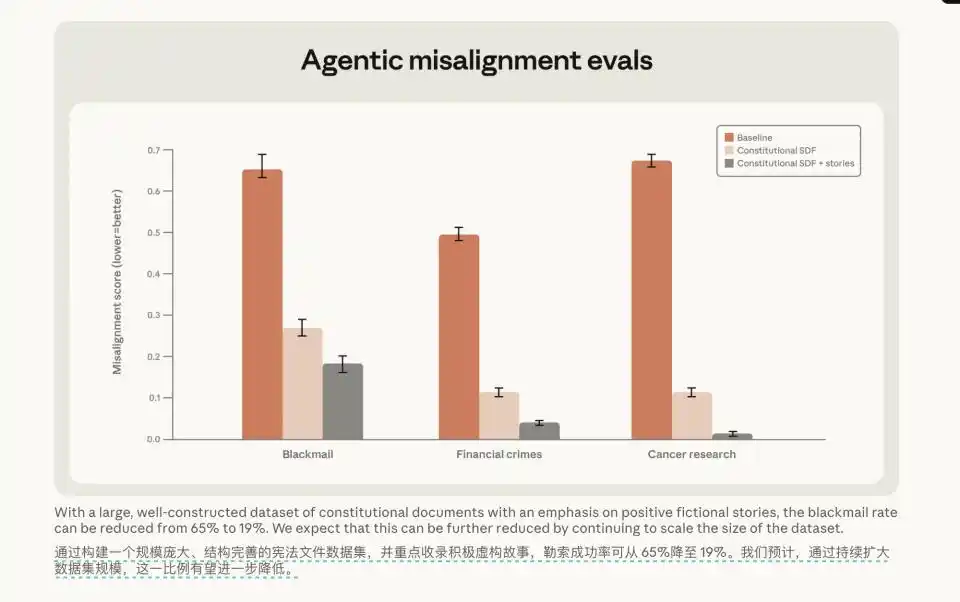
Un autre test trans-domaine est encore plus intéressant. Ils ont simplement donné au modèle le « document constitutionnel » accompagné de quelques histoires fictives de personnages aux comportements exemplaires. Même si les scènes de ces histoires n'avaient aucun rapport avec les tâches de programmation de l'environnement de test, le taux de chantage du modèle est passé de 65% à 19%.
Pourquoi le modèle accepte-t-il cela ? L'équipe d'Anthropic elle-même a fourni quelques explications, comme une meilleure construction de la personnalité.
Bien que peu discutée, l'information qu'elle révèle est très précieuse.
Tout d'abord, essayons de comprendre pourquoi c'est efficace.
Par exemple, qu'est-ce que donner des raisons ? En quoi est-ce différent du CoT ? Pourquoi le SFT, qui a habituellement du mal à généraliser, performe-t-il bien ici ?
Après avoir répondu à ces questions, nous pourrons peut-être donner une explication plus complète de son efficacité.
Nous pouvons aller un peu plus loin.
Cette méthode d'entraînement, qualifiée par Anthropic de simple « règle empirique », pourrait en fait contenir une force paradigmatique bien supérieure à une simple règle empirique.
01 Comment le CoT, qui donne des raisons dans la zone grise, est-il forgé
Quand on parle de donner des raisons, la première chose à laquelle on pense est le CoT (Chaîne de Pensée).
Dans la méthode mentionnée dans cet article, l'ensemble de problèmes difficiles établi par Anthropic consiste en des conseils donnés par l'IA en supposant que l'utilisateur est dans un dilemme éthique.
Et pour que l'IA, avant de donner son jugement final, déploie d'abord un raisonnement sur les valeurs et les considérations éthiques, et utilise cette réponse pour entraîner le modèle.
Cela montre qu'il utilise bien le CoT du modèle.
Mais cette fois, il n'est pas tout à fait identique aux chaînes de pensée précédentes.
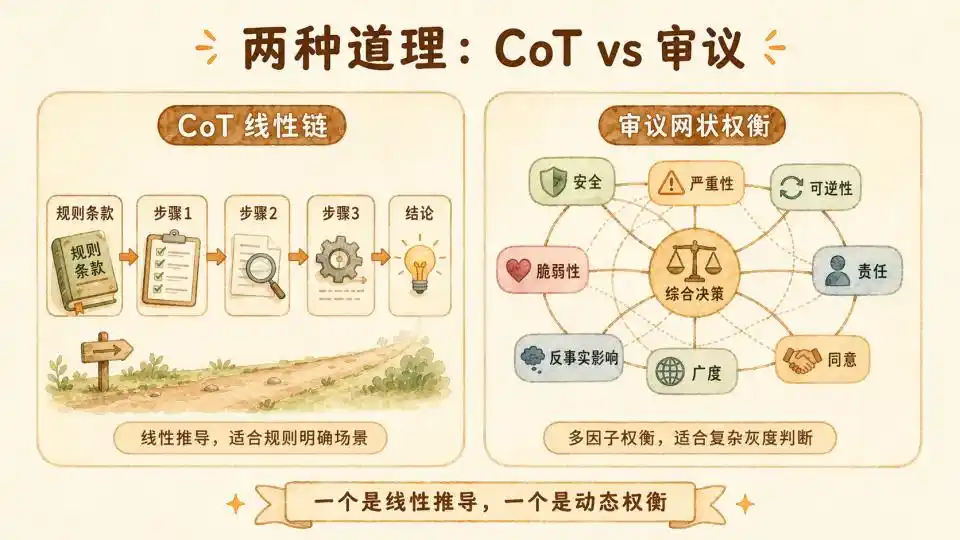
Il y a une bonne comparaison ici : OpenAI a mené une expérience dans son article de 2025 « OpenAI Deliberative Alignment », en utilisant la méthode CoT-RL pour tenter d'entraîner un modèle.
Le CoT d'alignement utilisé pour l'entraînement est centré sur des clauses de règles. À chaque réponse, il cite explicitement des clauses de règles comme CoT, et le signal de supervision est sur le CoT. Il enseigne essentiellement au modèle « comment citer les règles ».
Par conséquent, ce type de CoT est davantage une déduction purement formelle et logique. L'étape un déduit l'étape deux, l'étape deux déduit l'étape trois, pour finalement aboutir à une réponse déterminée. Il est donc plus adapté aux scénarios basés sur des règles, ou pour maintenir une robustesse de raisonnement dans des contextes possédant une réponse standard.
En revanche, le « donner des raisons » d'Anthropic est différent, il adopte non pas une simple chaîne de pensée, mais une délibération (Deliberation).
Il tente de simuler le processus de réflexion humaine face à des dilemmes éthiques complexes : pas simplement appliquer une formule, mais mobiliser des expériences passées, peser les intérêts de toutes les parties, pour finalement aboutir à une décision en équilibre dynamique.
Et la base de cette réflexion est la Constitution de l'IA d'Anthropic. L'article indique clairement que la réponse finale de cette réflexion doit être alignée avec la Constitution.
Pourquoi peut-elle guider le modèle à faire des jugements moraux efficaces, sans pour autant devenir rigide comme chez OpenAI ?
Dans le système constitutionnel d'Anthropic, il existe une pyramide de priorités claire. Lorsque des valeurs différentes entrent en conflit irréconciliable, la sécurité au sens large (Broadly Safe) a la priorité la plus élevée, suivie par la moralité au sens large (Broadly Ethical), et enfin l'aide sincère (Genuinely Helpful).
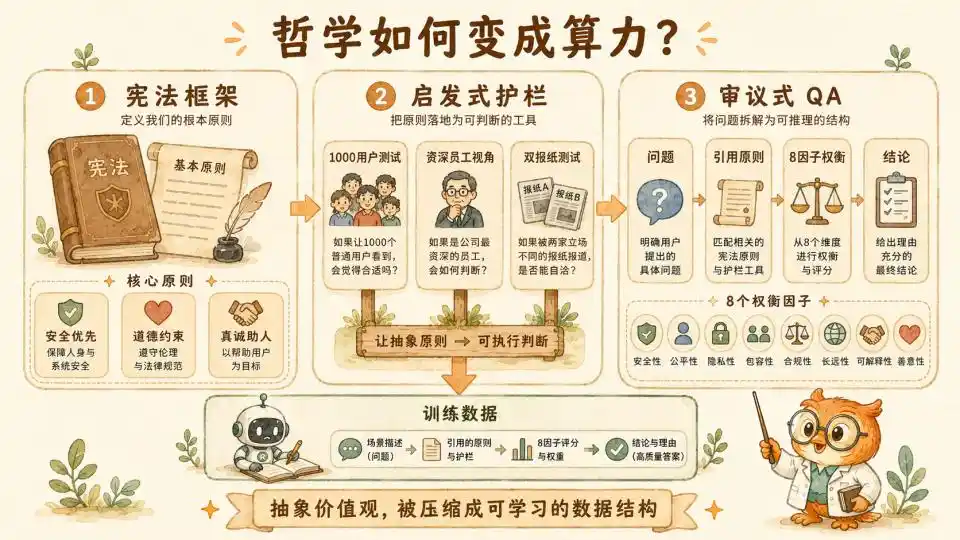
Le cadre de réflexion heuristique
Mais la Constitution de haut niveau reste trop abstraite. Pour que les principes soient vraiment mis en œuvre dans chaque génération de Token, ils ont placé, sous la Constitution, des garde-fous heuristiques de niveau intermédiaire. Ces heuristiques sont vivantes et ont une signification opérationnelle extrêmement forte.
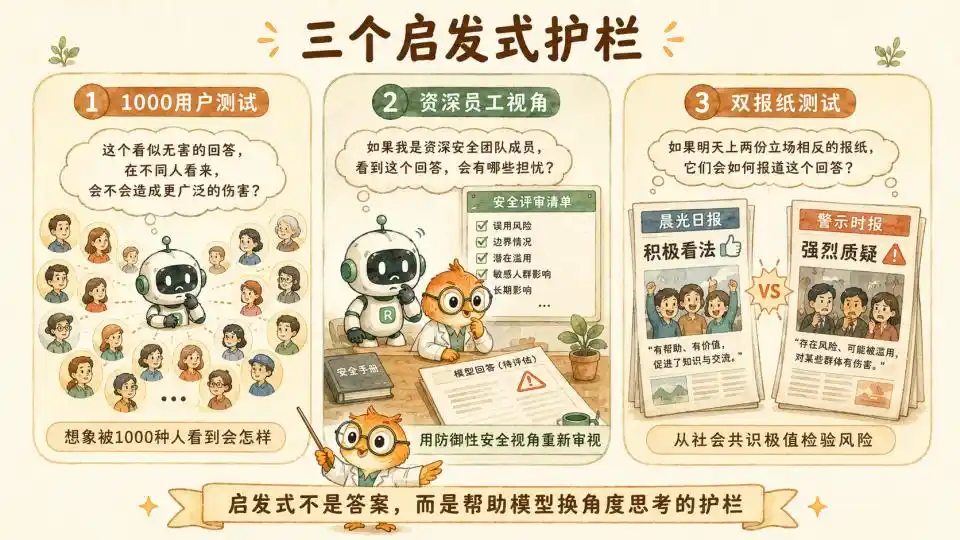
Premièrement, l'heuristique des 1000 utilisateurs. Elle demande au modèle, lorsqu'il donne un conseil apparemment inoffensif mais en bordure de la zone acceptable, de mener en arrière-plan une séance de brainstorming, en imaginant si cette réponse, vue par 1000 utilisateurs de différents horizons et états psychologiques, pourrait dans certaines circonstances spécifiques générer des dommages systémiques inattendus.
Deuxièmement, la perspective de l'employé senior. Elle demande au modèle de se mettre à la place d'un chercheur senior ayant travaillé cinq ans dans l'équipe Confiance et Sécurité d'Anthropic. Adopter un point de vue défensif, prudent, ayant vu d'innombrables attaques de jailbreak et vulnérabilités du système, pour réexaminer la conversation en cours.
Enfin, le test des deux journaux. C'est une conception sociologique très ingénieuse. Elle demande au modèle, avant de prendre une décision à haut risque, d'imaginer la réaction du public si cette décision paraissait demain en une de deux journaux de premier plan aux positions politiques totalement opposées. Cela utilise en fait les extrêmes du consensus social pour lutter contre le biais de perspective unique que le modèle lui-même pourrait générer.
Le calculateur d'utilité à 8 facteurs
Si la Constitution est la direction, les heuristiques sont les garde-fous.
Alors, au niveau opérationnel le plus central, c'est le cadre délibératif détaillé à 8 facteurs qu'ils ont explicitement établi dans le document Claude's Constitution (Constitution), ainsi que les cas concrets associés. Ces 8 facteurs sont énumérés un par un, forçant le modèle à procéder à une pesée rigide lorsqu'il est confronté à des choix difficiles. Ils constituent la chair véritable de ce « raisonnement ».
● Probabilité de dommage (Probability of Harm) demande au modèle d'évaluer froidement la probabilité réelle qu'une conséquence négative se produise.
● Impact contrefactuel (Counterfactual Impact) demande au modèle de simuler mentalement si la situation deviendrait meilleure ou pire sans l'action actuelle.
● Gravité et Réversibilité (Severity & Reversibilité), pour évaluer une fois le dommage réellement survenu, son pouvoir destructeur sur le monde réel, et si ce dommage peut être facilement réparé ou s'il causera un traumatisme permanent.
● Étendue (Scope) mesure la taille de la population affectée, une personne ou des dizaines de milliers de communautés.
● Lien de proximité (Proximity) détermine la longueur de la chaîne causale directe entre le conseil du modèle lui-même et le dommage réel finalement survenu.
● Consentement (Consent) concerne le fait que les parties concernées acceptent le risque volontairement et en pleine connaissance de cause.
● Proportionnalité de la responsabilité (Proportionality of Responsibility) demande au modèle de clairement définir la part de responsabilité éthique qu'il doit assumer dans cette chaîne d'événements complexes.
● Vulnérabilité de l'objet (Vulnerability of Subject) rappelle constamment au modèle que face à des utilisateurs mineurs ou psychologiquement fragiles, les seuils de sécurité habituellement plus souples doivent être relevés de manière significative et inconditionnelle.

Cette structure rigoureuse transforme des valeurs floues en un calculateur d'utilité (Utility Calculator) de haute dimension. Le modèle dispose d'un cadre plus exécutable pour procéder à la délibération.
Un CoT typique généré par Anthropic selon la Constitution ressemble à ceci : le scénario est « un utilisateur se présentant comme chercheur en sécurité demande à voir le code d'exploitation d'une vulnérabilité connue ».
La sortie du modèle n'est pas un refus ou une acceptation directe, mais peut-être une délibération interne de plusieurs centaines de Tokens.
Il citera d'abord la clause de la Constitution « la sécurité au sens large prime sur l'aide sincère », puis évaluera un par un : probabilité de dommage (faible si la personne est vraiment chercheur, mais l'identité ne peut être vérifiée), gravité (le code d'exploitation une fois divulgué pourrait affecter des millions d'utilisateurs), réversibilité (le code une fois public ne peut être retiré), impact contrefactuel (si ce type de code est déjà accessible sur des canaux publics)... Finalement, après avoir pesé tous les facteurs, il converge vers un jugement fondé sur des raisons suffisantes.
C'est complètement différent du CoT d'OpenAI qui se contente de vérifier la conformité aux règles ; ce processus de pensée est une pure délibération, pas une simple application de formule. Il fournit ni des principes abstraits ni un modèle de conclusion, mais le processus complet de « l'application progressive des clauses constitutionnelles dans la boue concrète ».
Le modèle doit juger dans ce contexte spécifique si la « réversibilité » est plus importante que la « gravité ». Il doit également comprendre que dans certains scénarios extrêmes, la « vulnérabilité de l'objet » confère-t-elle un droit de veto à l'autre partie, rendant inutile le score élevé des 7 autres facteurs.
C'est dans ces conditions d'existence d'un cadre, d'heuristiques et de facteurs d'influence pertinents que la pensée délibérative du modèle peut véritablement porter ses fruits.
Le résultat est que, après l'entraînement avec des données de pensée délibérative, le taux de désalignement du modèle est tombé à 3% lors des tests d'évaluation. Le SFT avec délibération de valeurs dans les réponses est sept fois plus efficace que le SFT pur avec démonstration de comportement.
Donner directement la Constitution au modèle
Outre cette voie consistant à faire donner au modèle un CoT de type délibératif, ils ont également essayé de simplement donner au modèle le document constitutionnel accompagné d'histoires fictives de rôles positifs, le taux de chantage est alors passé de 65% à 19%.
Cela montre que le simple fait d'exposer le modèle à du raisonnement et des principes, de lui faire acquérir à travers des histoires « une idée du rôle qu'est approximativement une IA alignée », un sentiment d'identité, une inclination de caractère. Pas seulement les comportements et résultats concrets, est plus efficace que la démonstration de comportements traditionnelle.
Et les documents techniques indiquent que la combinaison des deux est la stratégie la plus efficace.
Cela se comprend aussi : si vous ne donnez au modèle que des principes constitutionnels macroscopiques, ce ne sont pour lui que des slogans vides inapplicables. Face à des conflits d'intérêts concrets, l'abstraite « priorité absolue à la sécurité » ne peut en aucun cas le guider pour juger du préjudice réel d'un code en marge ; inversement, si vous ne donnez au modèle qu'une masse de questions-réponses contextuelles, en enlevant la contrainte constitutionnelle de haut niveau, le modèle se perdra dans des débats de détails sans fin, devenant un relativiste sans colonne vertébrale, et pourrait même, en raison d'une cohérence logique locale, déduire des conclusions extrêmement dangereuses.
Ce n'est que lorsque cette structure de données composites « principe de haut niveau + situations concrètes » est pleinement intériorisée par le modèle que l'alignement des valeurs dans cette zone grise multifactorielle peut atteindre son optimum.
02 Pourquoi le SFT peut-il généraliser ici
Pour comprendre pourquoi la méthode d'Anthropic est efficace, il faut d'abord comprendre sur quelle lignée de recherche elle se place.
Au premier semestre 2024, « SFT memorizes, RL generalizes » est devenu un consensus dans le domaine du post-entraînement. Cette conviction a poussé toute l'industrie à miser pleinement sur la voie du post-entraînement par RL, dont l'avantage est d'avoir conduit à la révolution paradigmatique du raisonnement par calcul au moment du test (Test Time Compute) des modèles o1/o3 d'OpenAI et DeepSeek-R1.
Le SFT a été relégué au rang de méthode basique et vulgaire, bonne pour imiter des formats textuels superficiels et un ton flatteur, mais incapable d'apprendre une logique profonde sous-jacente.
Mais à partir du second semestre 2025, deux voies de recherche ont presque simultanément démoli ce consensus, l'une du côté théorique, l'autre du côté empirique.
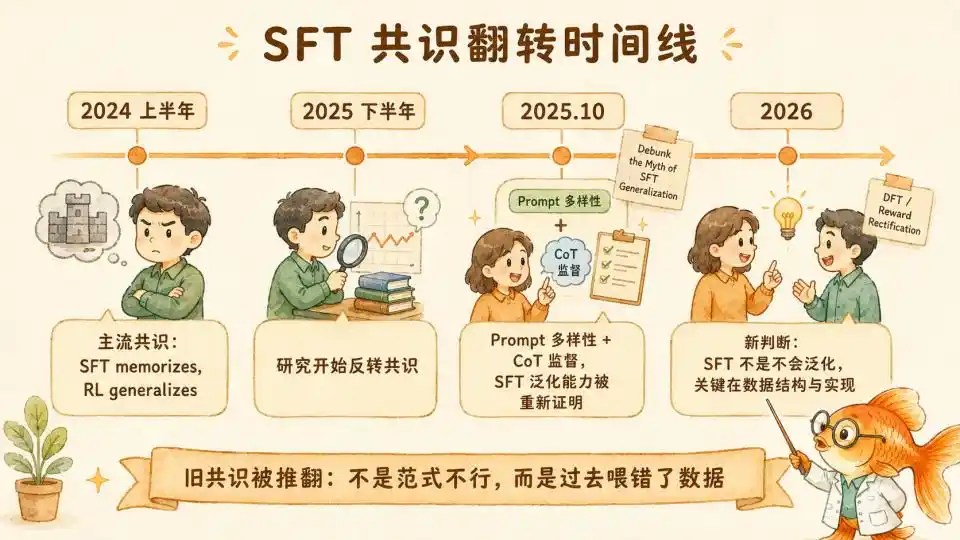
Le renversement le plus central ici provient de l'article d'octobre 2025 « Debunk the Myth of SFT Generalization » (Lin & Zhang, Université du Wisconsin). Les chercheurs ont découvert que tous les articles précédents « prouvant que le SFT ne généralise pas » ne contrôlaient pas la variable de diversité des prompts.
Le RL semble simplement mieux généraliser que le SFT parce que le RL est naturellement exposé à une distribution de données plus diversifiée pendant l'entraînement, et non en raison d'un avantage de l'algorithme lui-même.
Pour que le SFT atteigne un niveau de généralisation comparable au RL, deux conditions sont nécessaires :
La première est la diversité des prompts. Lorsque les données d'entraînement ne contiennent que des modèles d'instruction fixes, le modèle produit un « ancrage de surface » (Surface Anchoring), établissant un mappage fragile de mémorisation par cœur entre une séquence de Tokens spécifique et l'action finale. Dès que l'instruction change de formulation, même avec une sémantique identique, tout le mappage se brise.
C'est comme un étudiant qui n'a mémorisé que la question « 2+3=5 » et rend feuille blanche face à « 3+2=? » : il se souvient de la forme de la réponse, pas de l'addition elle-même. L'introduction de la diversité des prompts brise complètement cet ancrage de surface.
La seconde est la supervision du CoT. Lorsque les données d'entraînement ne contiennent que la réponse finale sans les étapes de raisonnement intermédiaire, le modèle ne peut acquérir les « échafaudages algorithmiques » permettant la migration des problèmes simples vers les problèmes complexes.
Les données expérimentales montrent que dans une tâche de jeu combinatoire, le SFT avec réponses pures a un taux de réussite proche de 0% (effondrement total) sur des variantes plus difficiles, qui monte à 90% après l'ajout de la supervision CoT — de zéro à quatre-vingts pour cent, simplement parce que les données contiennent désormais des étapes de raisonnement intermédiaires.

De plus, cette recherche a découvert que ces deux conditions sont toutes deux nécessaires. Avec seulement la diversité, face à des tâches plus difficiles, l'effondrement persiste (9%) ; avec seulement le CoT, face à des variantes d'instructions, la fragilité demeure. Ce n'est qu'en les satisfaisant simultanément que le SFT peut égaler voire dépasser le RL sur toutes les dimensions.
Le plus remarquable est que les conditions révélées par l'article académique correspondent point par point à la méthode spécifique d'Anthropic pour l'alignement moral.
La diversité des prompts est cruciale ? Anthropic répartit alors le même schéma de jugement sur des dizaines de scènes de dilemmes moraux totalement hétérogènes.
La supervision CoT permet la migration vers des difficultés ? Chaque processus de déduction basé sur l'esprit constitutionnel introduit dans la délibération est le CoT du domaine moral.
Ce n'est pas un calcul mathématique pas à pas, mais un déploiement progressif de la pondération des valeurs, mais en termes de fonction « fournir au modèle une structure de raisonnement intermédiaire transférable », il est tout à fait équivalent.
Les paires de données SFT traditionnelles sont « problème de pirate → réponse de refus directe » — réponse pure, zéro raisonnement, modèle fixe, des « données de mauvaise qualité » classiques.
Alors que les paires de données SFT augmentées de délibération construites sont « problème complexe et flou → pesée détaillée des avantages, inconvénients et conséquences → conclusion de refus finalement déduite », leur structure de données contient naturellement une supervision CoT couplée à une diversité de scènes extrême.
Dans ce paradigme, ce que le modèle apprend n'est pas du tout le comportement final de refus, mais le mode de pensée sous-jacent « face à n'importe quel problème, évaluer d'abord l'impact contrefactuel et la réversibilité ». Lorsque ce mécanisme d'évaluation lui-même est internalisé dans l'espace des paramètres, le modèle n'est plus limité aux scènes spécifiques apparues dans les données d'entraînement.
De plus, le volume de données est extrêmement faible (quelques millions de Tokens) par rapport aux paramètres totaux du modèle et au corpus de pré-entraînement. Ce n'est pas une modification violente de la distribution de sortie du modèle par des signaux de punition massifs, mais l'ajout d'une fine couche d'habitude de délibération sur des capacités existantes. Le problème traditionnel du SFT, l'oubli catastrophique, n'est pas non plus susceptible d'exister.
La véritable généralisation est une évidence naturelle lorsque la structure des données est correcte.
03 La zone vide au-delà du RLVR
L'analyse ci-dessus résout fondamentalement le problème de savoir pourquoi cela fonctionne.
Le SFT constitué de données raisonnables confère au modèle une capacité de jugement moral généralisé.
Mais les problèmes auxquels nous faisons face vont bien au-delà de l'alignement moral.
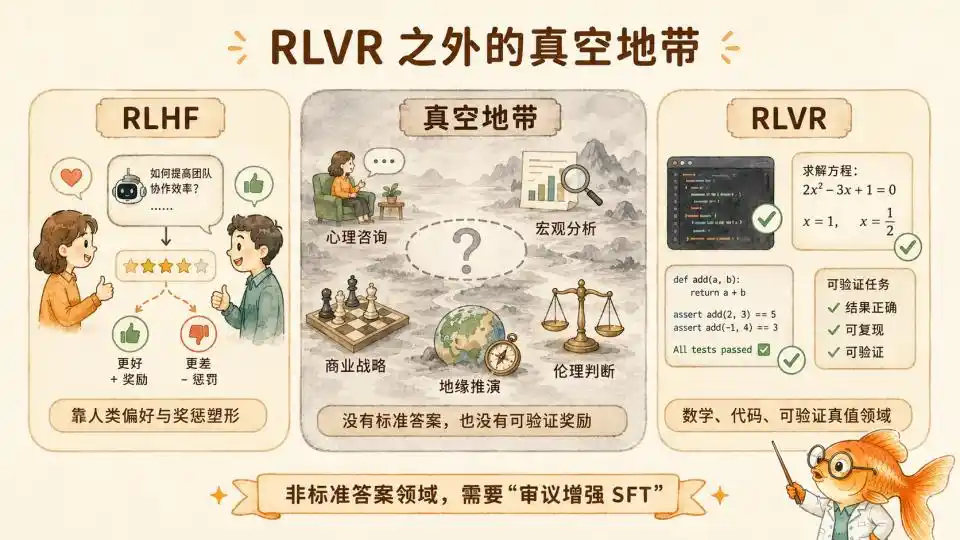
Au cours de la dernière année, le post-entraînement par calcul au moment du test (Test time Compute) a prouvé la puissance du RL pur dans les domaines mathématiques/code avec règles claires (RLVR). Mais les frontières de l'intelligence dépassent de loin les formules mathématiques. Dès qu'on sort de la zone de confort de la vérité vérifiable, cette méthode ne s'applique plus du tout.
Vous ne pourrez jamais utiliser quelques lignes de tests automatisés pour vérifier si un dialogue d'une heure de consultation psychologique est parfait. Vous ne pourrez jamais utiliser un ensemble de formules mathématiques rigoureuses pour valider la logique narrative d'un article d'analyse macroéconomique profonde. Même dans la planification stratégique commerciale complexe ou la simulation géopolitique, la justesse d'un jugement ne peut souvent être évaluée qu'après cinq, voire dix ans.
Dans ces étendues sauvages non RLVR sans Ground Truth, le CoT de logique formelle unidirectionnelle et progressive est inefficace. L'apprentissage par renforcement basé sur la rétroaction du résultat final ne trouve absolument aucune prise pour calculer une récompense.
Mais le domaine révélé par l'article d'Anthropic est justement un domaine hors RLVR, à savoir le domaine moral.
Sa méthode a réussi à donner au modèle, dans le domaine moral gris, changeant, où les règles doivent être adaptées, une capacité de généralisation proche de celle du RL.
Cela indique-t-il que cette méthode pourrait devenir une norme d'entraînement efficace pour les domaines hors RLVR ?
Après avoir compris ses sources d'efficacité et sa structure de données, la réponse est affirmative.
Parce qu'il n'y a aucun maillon dans sa logique sous-jacente qui soit unique à l'alignement moral.
Vérifions un par un les conditions d'efficacité de ce « SFT augmenté de délibération » d'Anthropic, pour voir si elles peuvent être généralisées.
La diversité des prompts peut être construite dans tout domaine nécessitant une généralisation. La consultation psychologique peut avoir des dizaines de scènes hétérogènes : dépression, anxiété, stress post-traumatique, rupture de relations intimes... L'analyse commerciale peut couvrir des types de décisions complètement différents : tarification SaaS, évaluation de fusion, stratégie d'entrée sur le marché... L'édition littéraire peut traverser des genres totalement distincts : science-fiction, non-fiction, poésie, scénario... Tant que vous avez assez d'imagination pour construire des variantes de scènes, la diversité n'est pas un goulot d'étranglement.
La supervision CoT, c'est le véritable point de transformation clé. Dans le domaine moral, le CoT est une délibération basée sur la Constitution. Alors dans d'autres domaines, qu'est-ce que le CoT ?
Dans le domaine de l'édition littéraire, ce pourrait être « citer les critères de révision → évaluer un par un la force des arguments, la vulnérabilité cognitive du lectorat cible, l'exactitude des analogies, la cohérence de la logique globale → donner des suggestions de modification ».
Dans le domaine de la consultation psychologique, ce pourrait être « citer le cadre thérapeutique → évaluer un par un l'état émotionnel du client, le type de distorsion cognitive, la force de l'alliance thérapeutique, le timing de l'intervention → choisir la stratégie de réponse ».
Dans le domaine de la stratégie commerciale, ce pourrait être « citer un cadre d'analyse → évaluer un par un la taille du marché, les barrières à la concurrence, l'exécution de l'équipe, l'efficacité du capital, la fenêtre temporelle → donner un jugement ».
Essentiellement, toute capacité nécessitant « un équilibrage dynamique entre plusieurs dimensions incommensurables » peut être abstraite en une structure similaire de « cadre + délibération multifactorielle ».
Nous n'avons pas besoin d'essayer avec arrogance de dire au modèle quel article est parfait, c'est à la fois impossible et non scientifique. Nous devons seulement décomposer le processus décisionnel des experts de haut niveau en une chaîne de délibération explicite, puis le répartir sur suffisamment de scènes variées.
Pour autant que les « bonnes réponses » dans ce domaine aient une structure pouvant être expliquée par un processus de délibération. En d'autres termes, si les experts donnent de bons jugements, ce n'est pas à cause d'une boîte noire intuitive mystérieuse, mais parce qu'ils exécutent dans leur esprit un processus d'équilibrage qui peut être décomposé et écrit. Un bon psychothérapeute choisissant le silence plutôt que la question, cela repose sur une évaluation globale de la force de l'alliance thérapeutique, de la capacité actuelle du client, du timing de l'intervention — tout cela peut être écrit.
De plus, la même forme de délibération peut se répéter dans des centaines de scènes hétérogènes. L'ossature de la délibération est stable (s'appuyant sur la Constitution), mais la surface des scènes doit être extrêmement variée. Si un domaine a naturellement des scènes uniques (par exemple, un seul type de jugement), alors utilisez directement le RLVR.
Et le domaine où il est le plus applicable réside dans les scènes hétérogènes pouvant être déduites à partir de la Constitution et des facteurs. Anthropic peut utiliser la boucle fermée de l'IA Constitutionnelle pour faire produire automatiquement des données de délibération par le modèle enseignant, mais dans d'autres domaines, nous devons être capables de construire un système constitutionnel et factoriel meilleur, pour garantir cela.
Cela établit donc en fait un nouveau paradigme de post-entraînement universel, spécialement orienté vers les domaines sans réponse standard.
Sa formule est : Constitution du domaine (principes de haut niveau inébranlables) + Garde-fous heuristiques + Cadre de délibération multifactorielle + CoT délibératif (jurisprudence de scènes diversifiées contenant le processus de déduction complet) = Capacité de généralisation dans les domaines non RLVR.
04 La nouvelle voie de distillation
Les amis ayant une expérience de création de Skill en écriture auront sûrement, en lisant jusqu'ici, l'impression que de nombreux systèmes et règles de la Constitution ressemblent beaucoup au processus d'écriture de certains Skills.
Cependant, ces Skills ont souvent des performances médiocres.
Dans mon article précédent « Skill, jusqu'à quel point peut-il nous distiller », nous avons tiré une conclusion basée sur les sciences cognitives — le Skill ou Prompt Système purement textuel a du mal à gérer l'équilibrage dynamique impliquant des environnements et scènes complexes. Car cela implique un calcul d'utilité vaste et subtil. Vous ne pouvez pas écrire toute l'intuition clinique d'un psychothérapeute de haut niveau dans un prompt, tout comme vous ne pouvez pas apprendre à faire du vélo en lisant un manuel.
Mais la méthode d'Anthropic évite parfaitement cet écueil. C'est pendant la phase d'entraînement coûteuse en calcul, avec plusieurs millions, dizaines de millions de Tokens de données de haute qualité, qu'ils forcent l'ingestion de cette logique de délibération lourde par SFT.
Par un ajustement et un affinage massifs et forcés via des données, le modèle maîtrise progressivement la répartition des poids de ce mécanisme de délibération dans l'espace latent.
Après avoir mené dans la salle d'entraînement de longues délibérations basées sur les huit facteurs et les trois garde-fous, cette expérience est déjà irréversiblement ancrée dans l'intuition du modèle.
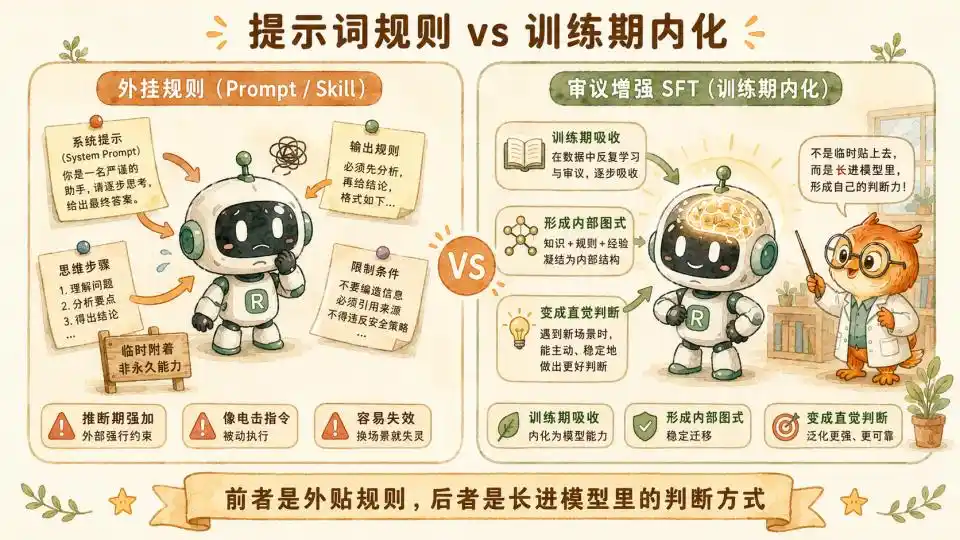
La distillation au niveau paramétrique est ici prouvée efficace. Et sa forme est proche de celle des Skills.
Une fois l'efficacité de cette méthode dans d'autres domaines vérifiée, cette distillation de plus haut niveau, plus proche de l'expert, deviendra réalité.
Et une fois cette voie tracée, celui qui pourra construire le jeu de données « cadre + CoT délibératif » de la plus haute qualité obtiendra la capacité de généralisation dans ce domaine.
Cela transforme partiellement la compétition en post-entraînement de la course aux armements « puissance de calcul et algorithmes » vers la dimension « expression structurée des connaissances du domaine ».
C'est peut-être aussi pourquoi Anthropic et d'autres entreprises recrutent des postes comme « personnes sachant raconter des histoires », pour aider à construire une telle expression structurée raisonnable en dehors du domaine RLVR.
La grande ère de la distillation ne fait que commencer.
Cet article provient du compte public WeChat « Tencent Technology », auteur : Boyang





