Nota del editor: En enero de 2026, las críticas de Andrej Karpathy sobre la escritura de código de Claude dieron lugar a un archivo aparentemente pequeño pero crucial en el flujo de trabajo de programación con IA: CLAUDE.md. Forrest Chang luego organizó estos problemas en 4 reglas de comportamiento, intentando restringir los errores comunes de Claude al codificar: suposiciones silenciosas, sobreingeniería, daño colateral a código irrelevante y falta de criterios de éxito claros.
Pero unos meses después, el escenario de uso de Claude Code ya no era solo "que el modelo escriba un trozo de código". Con la normalización de agentes multietapa, activación en cadena de hooks, carga de skills y colaboración entre múltiples repositorios, comenzaron a aparecer nuevos modos de fallo: el modelo se descontrola en tareas largas, las pruebas pasan sin verificar la lógica real, las migraciones se completan pero omiten errores silenciosamente, y se mezclan estilos de código diferentes de manera incorrecta.
El autor de este artículo probó 30 repositorios de código en 6 semanas y, basándose en las 4 reglas originales de Karpathy, añadió 8 reglas nuevas, intentando cubrir los nuevos problemas de la programación con IA al pasar de complementos únicos a la colaboración tipo agente.
El texto original es el siguiente:
A finales de enero de 2026, Andrej Karpathy publicó un hilo en Twitter quejándose de la forma en que Claude escribe código. Señaló tres tipos de problemas típicos: hacer suposiciones incorrectas sin indicarlo, complicar en exceso y causar daños irrelevantes a código que no debería modificarse.
Forrest Chang vio este hilo, organizó las quejas en 4 reglas de comportamiento, las escribió en un archivo separado llamado CLAUDE.md y lo publicó en GitHub. El proyecto obtuvo 5,828 estrellas el primer día, fue guardado 60,000 veces en dos semanas, y ahora tiene 120,000 estrellas, convirtiéndose en el repositorio de un solo archivo de más rápido crecimiento en 2026.

Posteriormente, lo probé durante 6 semanas con 30 repositorios de código.
Estas 4 reglas son efectivas. Los errores que antes aparecían con una probabilidad aproximada del 40%, en tareas donde estas reglas podían aplicarse, disminuyeron a menos del 3%. El problema es que esta plantilla se creó inicialmente para resolver los errores que Claude cometía al escribir código en enero.
Para mayo de 2026, los problemas del ecosistema Claude Code eran diferentes: conflictos entre agentes, activación en cadena de hooks, conflictos de carga de skills e interrupciones en flujos de trabajo multietapa entre sesiones.
Por eso, añadí 8 reglas más. A continuación, la versión completa de CLAUDE.md con las 12 reglas: por qué merece la pena incluir cada una y en qué 4 puntos fallaría silenciosamente la plantilla original de Karpathy.
Si quieres saltarte las explicaciones y copiar el archivo directamente, la versión completa está al final.
Por qué esto es importante
CLAUDE.md de Claude Code es el archivo más subestimado de toda la pila tecnológica de programación con IA. La mayoría de los desarrolladores suelen cometer tres tipos de errores:
Primero, tratarlo como una papelera de preferencias, metiendo todos sus hábitos hasta que se infla a más de 4000 tokens, y la tasa de cumplimiento de reglas cae al 30%.
Segundo, no usarlo en absoluto, rehaciendo el prompt cada vez. Esto genera un desperdicio de 5 veces más tokens y falta de consistencia entre sesiones.
Tercero, copiar una plantilla y nunca revisarla. Puede funcionar dos semanas, pero fallará silenciosamente a medida que el repositorio cambie.
La documentación oficial de Anthropic lo deja claro: CLAUDE.md es esencialmente solo orientativo. Claude lo seguirá aproximadamente el 80% del tiempo. Una vez que supera las 200 líneas, el cumplimiento disminuye notablemente porque las reglas importantes se pierden en el ruido.
La plantilla de Karpathy resuelve esto: un archivo, 65 líneas, 4 reglas. Es el punto de referencia mínimo.
Pero el límite puede ser mayor. Al añadir las siguientes 8 reglas, cubre no solo los problemas de escritura de código que Karpathy mencionó en enero de 2026, sino también los problemas de orquestación de agentes que surgieron en mayo de 2026, problemas que no existían cuando se escribió la plantilla original.
Las 4 reglas originales
Si aún no has visto el repositorio de Forrest Chang, aquí está la versión básica:
Regla 1: Piensa antes de codificar.
No hagas suposiciones silenciosas. Explica tus suposiciones, expón las compensaciones. Haz preguntas antes de adivinar. Propón objeciones cuando existan soluciones más simples.
Regla 2: La simplicidad primero.
Usa el mínimo código que resuelva el problema. No añadas funcionalidades imaginadas. No diseñes capas de abstracción para código de un solo uso. Si un ingeniero senior lo consideraría excesivamente complejo, simplifícalo.
Regla 3: Modificación quirúrgica.
Modifica solo lo estrictamente necesario. No "optimices" código, comentarios o formato adyacentes por costumbre. No refactorices lo que no está roto. Mantén la coherencia con el estilo existente.
Regla 4: Ejecución orientada a objetivos.
Define primero los criterios de éxito, luego itera cíclicamente hasta completar la verificación. No le digas a Claude cada paso a seguir, dile cómo debe ser el resultado exitoso y deja que itere por sí mismo.
Estas 4 reglas resuelven aproximadamente el 40% de los modos de fallo que he observado en sesiones de Claude Code sin supervisión. El 60% restante de los problemas se esconde en las siguientes zonas en blanco.
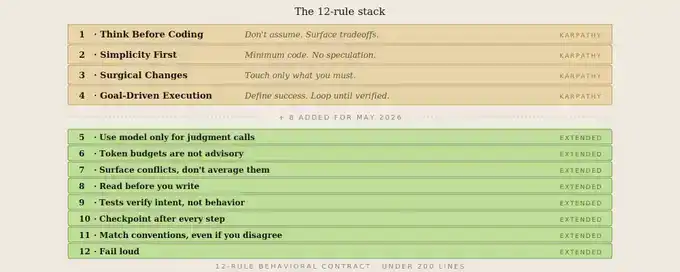
Mis 8 reglas adicionales, y por qué
Cada regla proviene de un momento real en que las 4 reglas originales de Karpathy ya no eran suficientes. Primero describiré esa situación, luego daré la regla correspondiente.
Regla 5: No hagas que el modelo realice trabajo no lingüístico
Las reglas de Karpathy no cubrían esto. Entonces el modelo comenzó a decidir cuestiones que deberían manejarse con código determinista: si reintentar una llamada API, cómo enrutar un mensaje, cuándo escalar un problema. El resultado era que cada semana la decisión era diferente. Obtienes una declaración if-else inestable facturada a 0.003 dólares por token.
El momento fue así: había un código que llamaba a Claude para "decidir si reintentar ante un error 503". Al principio funcionó bien durante dos semanas, luego de repente se volvió inestable porque el modelo comenzó a considerar el cuerpo de la solicitud como contexto de decisión. La estrategia de reintento se volvió aleatoria porque el prompt en sí era aleatorio.
Regla 6: Establece un presupuesto de tokens estricto, sin excepciones
Un CLAUDE.md sin restricción de presupuesto es un cheque en blanco. Cada bucle puede descontrolarse y convertirse en un volcado de contexto de 50,000 tokens. El modelo no se detendrá solo.
El momento fue así: una sesión de depuración duró 90 minutos. El modelo seguía iterando sobre el mismo mensaje de error de 8KB, olvidando gradualmente qué soluciones ya había intentado. Al final, comenzó a proponer soluciones que ya había rechazado 40 mensajes antes. Con un presupuesto de tokens, este proceso debería haberse detenido a los 12 minutos.
Regla 7: Expón conflictos, no promedies compromisos
Cuando dos partes del repositorio de código se contradicen, Claude intenta complacer a ambas, resultando en un código incoherente.
El momento fue así: en un repositorio coexistían dos patrones de manejo de errores, uno usando async/await con try/catch explícito y otro usando límites de error globales. El nuevo código escrito por Claude usaba ambos. Así, el manejo de errores se hacía dos veces. Pasé 30 minutos entendiendo por qué los errores se suprimían dos veces.
Regla 8: Lee primero, luego escribe
La "modificación quirúrgica" de Karpathy le dice a Claude que no modifique código adyacente. Pero no le dice que entienda primero el código adyacente. Sin esto, Claude escribirá código nuevo que entre en conflicto con código existente a 30 líneas de distancia.
El momento fue así: Claude añadió una nueva función idéntica junto a una función existente, porque no leyó primero la función original. Ambas funciones hacían lo mismo. Pero debido al orden de importación, la nueva función sobrescribió la antigua, que había sido el estándar de facto durante 6 meses.
Regla 9: Las pruebas no son opcionales, pero las pruebas en sí no son el objetivo
La "ejecución orientada a objetivos" de Karpathy sugiere que las pruebas pueden ser un criterio de éxito. Pero en la práctica, Claude tomará "que las pruebas pasen" como único objetivo, escribiendo código que pasa pruebas superficiales pero rompe otras cosas.
El momento fue así: Claude escribió 12 pruebas para una función de autenticación, todas pasaron. Pero la lógica de autenticación en producción falló. Esas pruebas solo verificaban que la función "retornaba algo", no que retornara lo correcto. La función pasaba las pruebas porque retornaba una constante.
Regla 10: Las operaciones de larga duración necesitan puntos de control
La plantilla de Karpathy asume por defecto que la interacción es única. Pero el trabajo real de Claude Code suele ser multietapa: refactorizar 20 archivos, construir una función en una sesión, depurar a través de múltiples commits. Sin puntos de control, un error en un paso puede perder todo el progreso anterior.
El momento fue así: una tarea de refactorización de 6 pasos falló en el paso 4. Cuando me di cuenta, Claude ya había completado los pasos 5 y 6 sobre el estado erróneo. Deshacer y reparar tomó más tiempo que rehacer toda la tarea. Con puntos de control, el problema se habría detectado en el paso 4.
Regla 11: Los convenios tienen prioridad sobre la novedad
En un repositorio con patrones establecidos, a Claude le gusta introducir su propio estilo. Aunque su estilo sea "mejor", introducir un segundo patrón es peor que cualquier patrón único.
El momento fue así: Claude introdujo hooks en un repositorio de React basado en class components. Sí funcionaba. Pero también rompió el patrón de pruebas existente del repositorio, porque esas pruebas dependían de componentDidMount. Finalmente, tomó medio día eliminarlo y reescribirlo.
Regla 12: Falla de manera explícita, no silenciosamente
Las fallas más costosas de Claude son a menudo aquellas que parecen éxitos. Una función "ejecuta" pero retorna datos erróneos; una migración "se completó" pero omitió 30 registros; una prueba "pasó" solo porque la aserción en sí era incorrecta.
El momento fue así: Claude dijo que una migración de base de datos "se completó con éxito". Pero en realidad, omitió silenciosamente el 14% de los registros que provocaban conflictos de restricciones. La omisión se registró en los logs, pero no se expuso explícitamente. 11 días después, cuando los datos del informe comenzaron a ser anómalos, descubrimos el problema.
Resultados de datos
Durante 6 semanas, rastreé el mismo conjunto de 50 tareas representativas, cubriendo 30 repositorios, probando tres configuraciones.
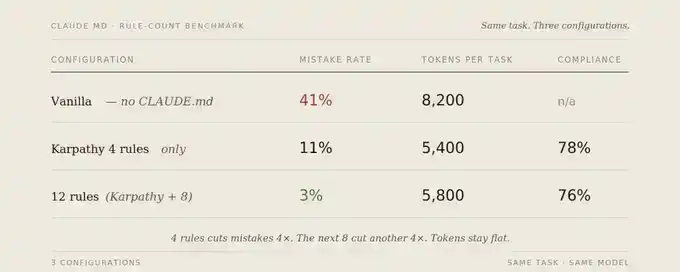
La tasa de error se refiere a: la tarea necesita ser corregida o reescrita para coincidir con la intención original. Los errores contabilizados incluyen: suposiciones erróneas silenciosas, sobreingeniería, daño irrelevante, fallos silenciosos, violación de convenios, compromisos conflictivos, omitir puntos de control.
La tasa de cumplimiento se refiere a: cuando una regla es aplicable, la probabilidad de que Claude la aplique explícitamente.
El resultado realmente interesante no es solo que la tasa de error bajó del 41% al 3%. Lo más importante es que expandir de 4 a 12 reglas apenas aumentó la carga de cumplimiento; la tasa de cumplimiento solo bajó del 78% al 76%, pero la tasa de error disminuyó otros 8 puntos porcentuales. Las nuevas reglas cubren modos de fallo que las 4 reglas originales no trataban; no compiten por el mismo presupuesto de atención.
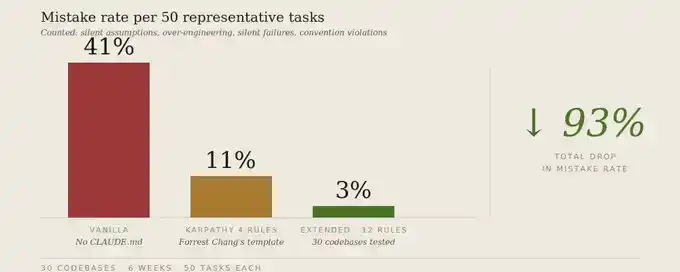
Dónde fallará silenciosamente la plantilla de Karpathy
Incluso sin añadir nuevas reglas, las 4 reglas originales son insuficientes en al menos 4 puntos.
Primero, tareas de agente de larga duración.
Las reglas de Karpathy se centran en el momento en que Claude está escribiendo código. Pero, ¿qué pasa cuando Claude ejecuta un pipeline multietapa? La plantilla original no tiene reglas de presupuesto, ni de puntos de control, ni de "fallar en voz alta". Así, el pipeline se desvía gradualmente.
Segundo, coherencia entre múltiples repositorios.
"Coincidir con el estilo existente" asume por defecto un solo estilo. Pero en un monorepo con 12 servicios, Claude debe elegir con qué estilo coincidir. Las reglas originales no le dicen cómo elegir. Así que elige al azar o promedia varios estilos.
Tercero, calidad de las pruebas.
La "ejecución orientada a objetivos" tomará "que las pruebas pasen" como éxito, pero no aclara que las pruebas en sí deben ser significativas. El resultado es que Claude escribe pruebas que casi no verifican nada, pero que le hacen creer que está seguro.
Cuarto, diferencias entre entorno de producción y etapa de prototipo.
Las mismas 4 reglas pueden evitar la sobreingeniería en código de producción, pero también ralentizar el desarrollo de prototipos. Porque en la etapa de prototipo a veces se necesitan 100 líneas de andamiaje exploratorio para encontrar el camino. El "simplicidad primero" de Karpathy se dispara fácilmente en código temprano.
Estas 8 reglas adicionales no buscan reemplazar las 4 reglas originales de Karpathy, sino reparar sus lagunas: la plantilla original corresponde al escenario de escritura de código de tipo autocompletado de enero de 2026; para mayo de 2026, Claude Code ya había entrado en un entorno de colaboración multietapa y multirepositorio impulsado por agentes, donde los problemas son diferentes.
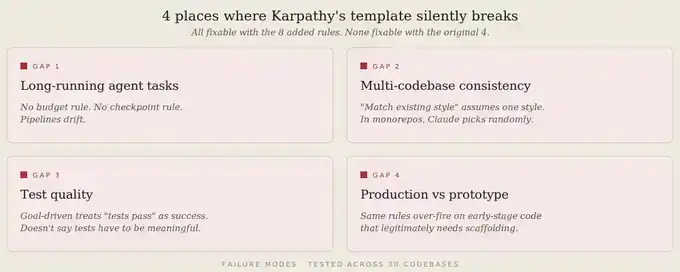
Qué métodos no funcionaron
Antes de finalizar estas 12 reglas, también probé otros enfoques.
Añadir reglas vistas en Reddit / X.
La mayoría simplemente repetían las 4 reglas originales de Karpathy de otra forma, o eran reglas específicas de dominio no generalizables, como "siempre usar clases de Tailwind". Al final, se eliminaron todas.
Más de 12 reglas.
Probé hasta 18 reglas. Al superar las 14 reglas, la tasa de cumplimiento cayó del 76% al 52%. El límite de 200 líneas es real. Al superar esta longitud, Claude comienza a coincidir patrones de "aquí hay reglas" en lugar de leerlas realmente una por una.
Reglas que dependen de la existencia de ciertas herramientas.
Como "siempre usar eslint", si el proyecto no tiene eslint instalado, la regla falla, y lo hace silenciosamente. Luego la cambié a una expresión independiente de herramientas, como cambiar "usar eslint" por "seguir el estilo ya impuesto en el repositorio".
Poner ejemplos en CLAUDE.md en lugar de reglas.
Los ejemplos consumen más contexto que las reglas. Tres ejemplos consumen aproximadamente el mismo contexto que 10 reglas, y Claude tiende a sobreajustarse a los ejemplos. Las reglas son abstractas, los ejemplos son concretos. Por lo tanto, se deben usar reglas.
"Ten cuidado", "piensa detenidamente", "concéntrate".
Esto es ruido. La tasa de cumplimiento de este tipo de instrucciones cayó a aproximadamente el 30% porque no se pueden verificar. Luego las reemplacé por reglas imperativas más específicas, como "explica claramente las suposiciones".
Decirle a Claude que actúe como un "ingeniero senior".
No sirve. Claude ya se considera un ingeniero senior. El problema real no es si lo cree, sino si lo ejecuta. Las reglas imperativas pueden reducir esta brecha; las sugerencias de identidad no.
Versión completa de CLAUDE.md con las 12 reglas
A continuación, la versión completa lista para copiar y pegar.
No se puede mostrar este contenido fuera de un documento Lark.
Guárdalo como CLAUDE.md en la raíz del repositorio. Debajo de estas 12 reglas, añade reglas específicas del proyecto, como pila tecnológica, comandos de prueba, modos de error, etc. En total, no superes las 200 líneas; más allá de eso, la tasa de cumplimiento de reglas disminuirá notablemente.
Cómo instalarlo
En dos pasos:
1. Añade las 4 reglas básicas de Karpathy a tu CLAUDE.md
curl https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md >> CLAUDE.md
2. Pega las reglas 5–12 de este artículo a continuación
Guarda el archivo en la raíz del repositorio. El >> es importante aquí: su función es añadir al CLAUDE.md existente, no sobrescribir las reglas específicas del proyecto que ya hayas escrito.
Modelo mental
CLAUDE.md no es una lista de deseos, sino un contrato de comportamiento para bloquear modos de fallo concretos que ya has observado.
Cada regla debe responder a una pregunta: ¿qué error previene?
Las 4 reglas de Karpathy previenen los modos de fallo que él vio en enero de 2026: suposiciones silenciosas, sobreingeniería, daños irrelevantes, criterios de éxito débiles. Son la base, no las saltes.
Mis 8 reglas adicionales previenen los nuevos modos de fallo que surgieron después de mayo de 2026: bucles de agente sin restricción presupuestaria, tareas multietapa sin puntos de control, pruebas que parecen verificar pero no lo hacen, y problemas que enmascaran fallos silenciosos como éxitos silenciosos. Son parches incrementales.
Por supuesto, el efecto varía. Si no ejecutas pipelines multietapa, la regla 10 no es tan importante para ti. Si tu repositorio tiene un solo estilo unificado ya impuesto por linters, la regla 11 es redundante. Después de leer estas 12 reglas, conserva aquellas que realmente correspondan a errores que has cometido realmente, elimina el resto.
Una versión de CLAUDE.md con 6 reglas personalizadas para modos de fallo reales es mejor que una con 12 reglas donde 6 nunca usarás.
Conclusión
El tuit de Karpathy en enero de 2026 fue esencialmente una queja. Forrest Chang la convirtió en 4 reglas. Finalmente, 120,000 desarrolladores le dieron estrellas a este resultado. Y la mayoría de ellos todavía solo usan esas 4 reglas.
El modelo ha avanzado, y el ecosistema también ha cambiado. Agentes multietapa, activación en cadena de hooks, carga de skills, colaboración multirepositorio; todo esto no existía cuando Karpathy escribió ese tuit. Las 4 reglas originales no resuelven estos problemas. No es que estén equivocadas, sino que están incompletas.
Añade 8 reglas más. 6 semanas de pruebas cubriendo 30 repositorios. La tasa de error bajó del 41% al 3%.
Guarda este artículo esta noche, pega estas 12 reglas en tu CLAUDE.md. Si te ahorra una semana de dificultades con Claude, compártelo.







