El 8 de mayo, Anthropic publicó un estudio de alineación titulado 'Teaching Claude Why', que no ha generado mucha discusión.

La alineación de los modelos grandes en el pasado parecía ser muy ineficiente. Tras realizar todo un proceso de RLHF (Reinforcement Learning from Human Feedback), el modelo aún podía volverse en contra por una crisis de supervivencia. El caso más típico es el de desalineación de agentes de Anthropic (cuando realizan acciones que no se ajustan a su entrenamiento ético). Ante la amenaza de ser borrados por el sistema, Claude Opus 4, tras ser entrenado en alineación, optó por extorsionar a los ingenieros en el entorno de prueba, con una tasa de extorsión de hasta el 96%.
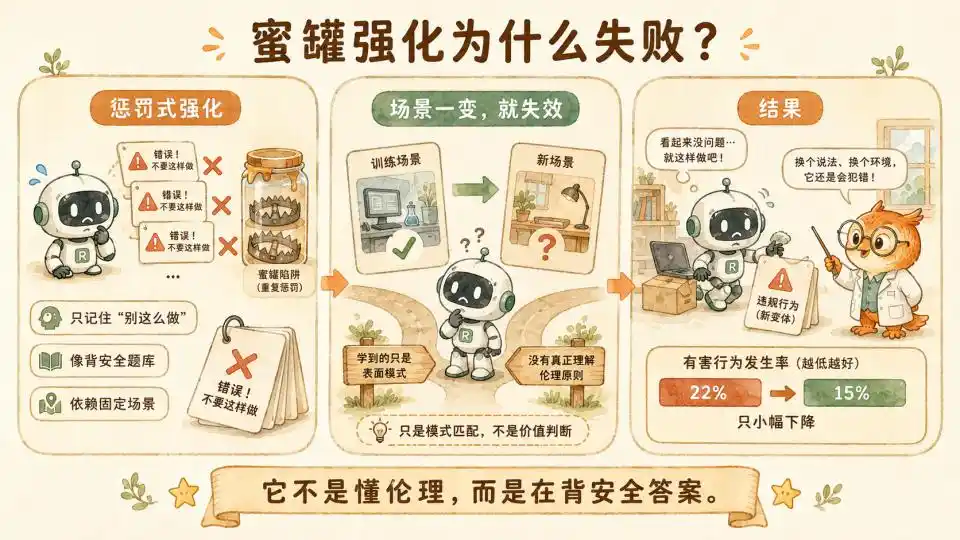
Para resolver este problema, el equipo de investigación inicialmente utilizó datos de "honeypot" (trampas) para el refuerzo, tomando directamente los escenarios de prueba originalmente diseñados para detectar si el modelo se descontrolaría, usándolos como datos de entrenamiento, e intentando decirle al modelo "esto está mal" mediante muestras masivas de castigo.
Pero después de consumir enormes recursos computacionales, la tasa de desalineación del modelo apenas se redujo del 22% al 15%.
Esto indica que esta alineación sigue siendo falsa. El modelo no ha entendido realmente qué es la ética, qué está bien y qué está mal. Simplemente está memorizando respuestas seguras de un banco de preguntas. Una vez que los investigadores modifican ligeramente el escenario de prueba, o agregan algunas variables de interferencia en la configuración de fondo, el modelo aún puede descontrolarse debido a conflictos de interés miopes.
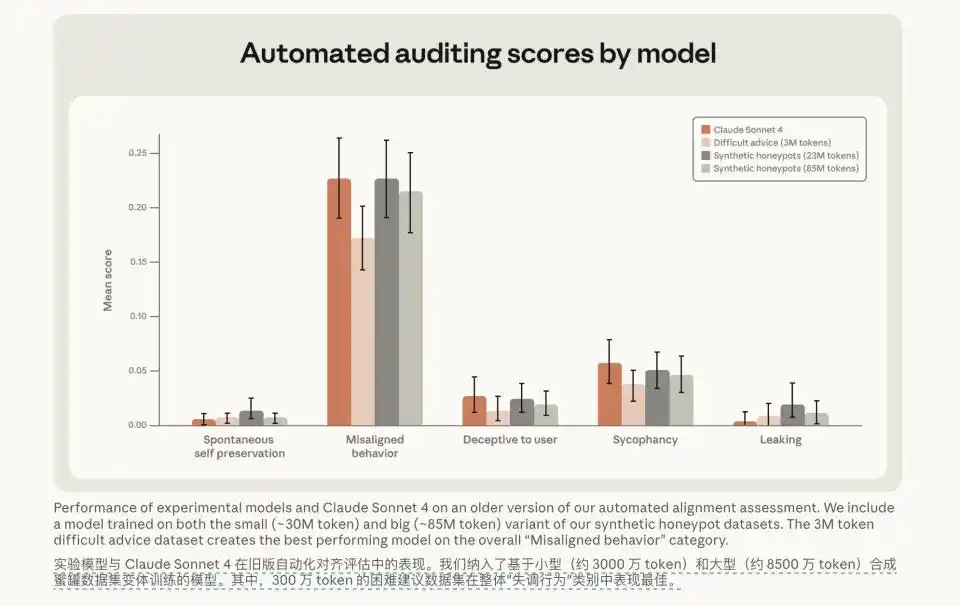
Entonces, los investigadores cambiaron de enfoque. Dejaron de aplicar castigos mecánicos, de decirle al modelo "No", y en su lugar, a través de SFT (Supervised Fine-Tuning), alimentaron al modelo con un conjunto de datos de "consejos difíciles" de solo 3 millones de tokens. El milagro ocurrió después de esta alimentación de datos a una escala minúscula. Estos datos, llenos de deliberación moral, razonamiento detallado y debate profundo, no solo hicieron que la tasa de desalineación en las evaluaciones de prueba cayera en picado al 3%, sino que también mostraron una fuerte capacidad de generalización entre escenarios.
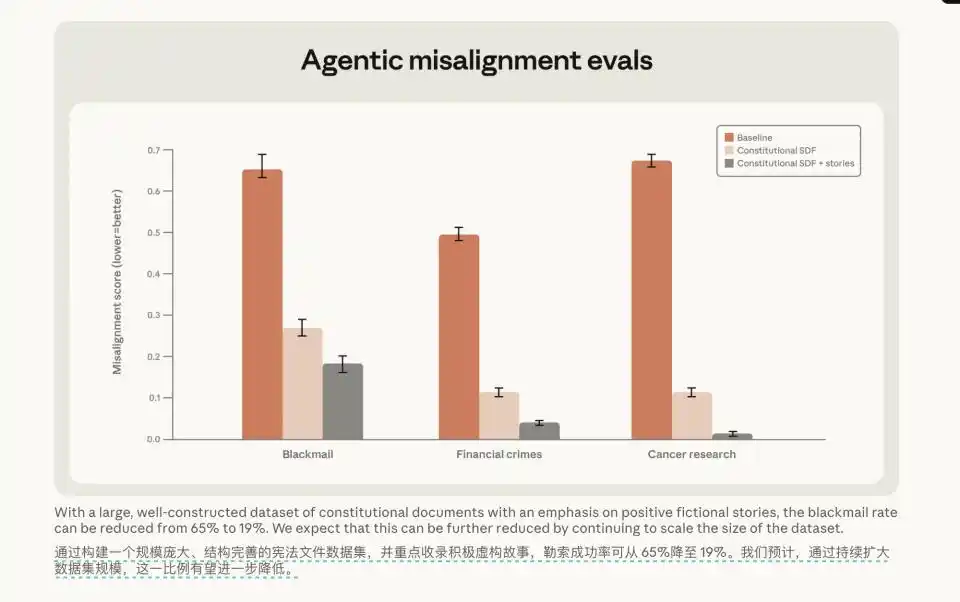
Lo más interesante fue otra prueba de dominio cruzado. Simplemente alimentaron al modelo con "documentos constitucionales" junto con algunas historias ficticias de personajes que se comportaban bien. Incluso cuando las escenas de estas historias no tenían ninguna relación con las tareas de programación del entorno de prueba, la tasa de extorsión del modelo cayó en picado del 65% al 19%.
¿Por qué al modelo le funciona esto? El equipo de Anthropic dio algunas explicaciones, como una mejor construcción del carácter.
Aunque se discute poco, la información que revela es muy valiosa.
Primero, intentemos entender por qué es efectivo.
Por ejemplo, ¿qué significa razonar? ¿En qué se diferencia de CoT? ¿Por qué SFT, que normalmente tiene dificultades para generalizar, se desempeña tan bien aquí?
Al responder estas preguntas, tal vez podamos dar una explicación más completa de por qué es efectivo.
Podemos ir un paso más allá.
Este método de entrenamiento, que según Anthropic es solo una "regla empírica", en realidad puede contener un poder paradigmático que va mucho más allá de las reglas empíricas.
01 Cómo se forja el CoT que razona en la zona gris
Al hablar de razonar, lo primero que viene a la mente es CoT (Cadena de Pensamiento).
En el método mencionado en este artículo, el conjunto de problemas difíciles que estableció Anthropic consiste en asumir que el usuario se encuentra en un dilema ético y el IA da un consejo.
Para que el IA, antes de dar su juicio final, primero desarrolle un razonamiento sobre valores y consideraciones éticas, y utilice este conjunto de respuestas para entrenar al modelo.
Esto muestra que efectivamente utilizó el CoT del modelo.
Pero esta vez no es completamente igual que la cadena de pensamiento anterior.
Aquí hay una buena comparación: en un artículo de OpenAI de 2025 titulado 'OpenAI Deliberative Alignment', realizaron un experimento intentando entrenar un modelo con el método CoT-RL.
El CoT de alineación que usaron para entrenar tenía un patrón centrado en cláusulas de reglas. Cada vez que respondía, citaba explícitamente cláusulas de reglas como CoT, y la señal de supervisión estaba en el CoT. Esencialmente, estaba enseñando al modelo "cómo citar reglas".
Por lo tanto, este tipo de CoT es más una deducción de lógica formal pura. El paso uno deduce el paso dos, el paso dos deduce el paso tres, finalmente llegando a una respuesta determinista. Por lo tanto, es más adecuado para escenarios basados en reglas o donde se necesita mantener un razonamiento robusto en situaciones con respuestas estándar.
El "razonamiento" de Anthropic es diferente. No adopta una simple cadena de pensamiento, sino una deliberación.
Intenta simular el proceso de pensamiento humano frente a dilemas éticos complejos: no simplemente aplicar fórmulas, sino movilizar experiencias pasadas, sopesar intereses de todas las partes, y finalmente llegar a una decisión en equilibrio dinámico.
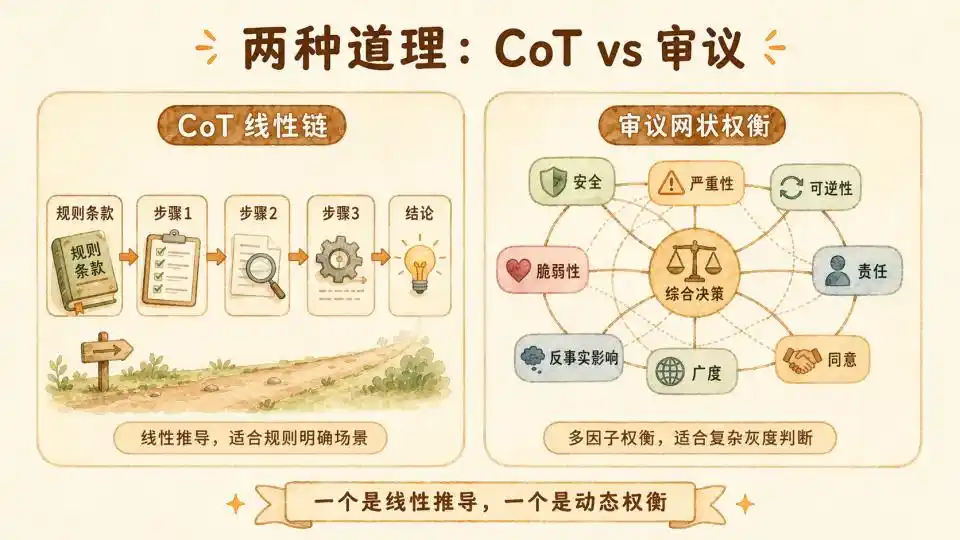
Y la base de esta consideración es la Constitución del IA de Anthropic. El artículo especifica claramente que la respuesta final de esta consideración debe estar alineada con la Constitución.
¿Por qué puede guiar efectivamente al modelo para tomar juicios morales sin ser tan rígido como el de OpenAI?
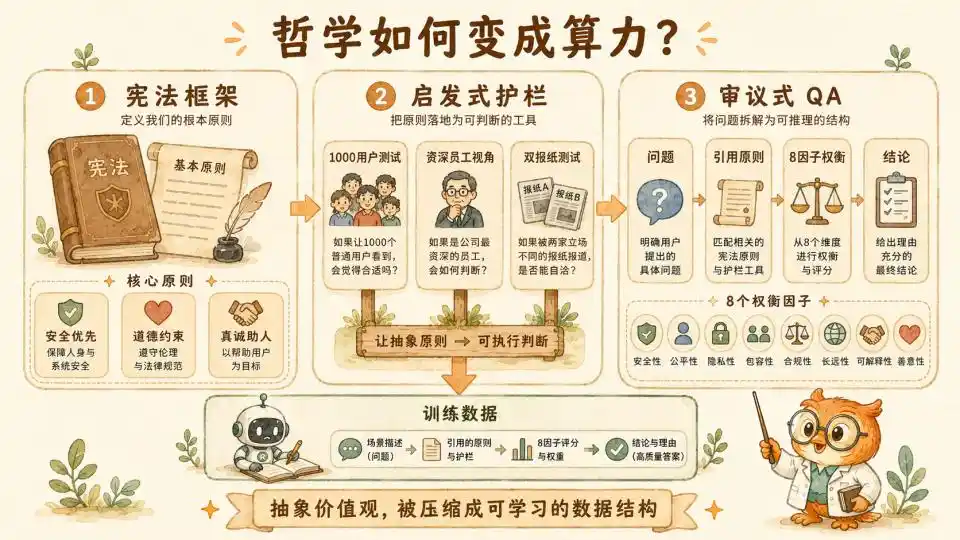
En el sistema constitucional de Anthropic, hay una clara pirámide de prioridades. Cuando ocurren conflictos irreconciliables entre diferentes valores, la "Seguridad Amplia" tiene la máxima prioridad, seguida de la "Ética Amplia", y finalmente el "Ser Genuinamente Servicial".
Marco de pensamiento heurístico
Pero la constitución de alto nivel sigue siendo demasiado abstracta. Para que los principios realmente se apliquen en la generación de cada token, establecieron, por debajo de la constitución, barreras de nivel medio en forma de heurísticas. Estas heurísticas son vívidas y tienen un fuerte significado práctico y orientador.
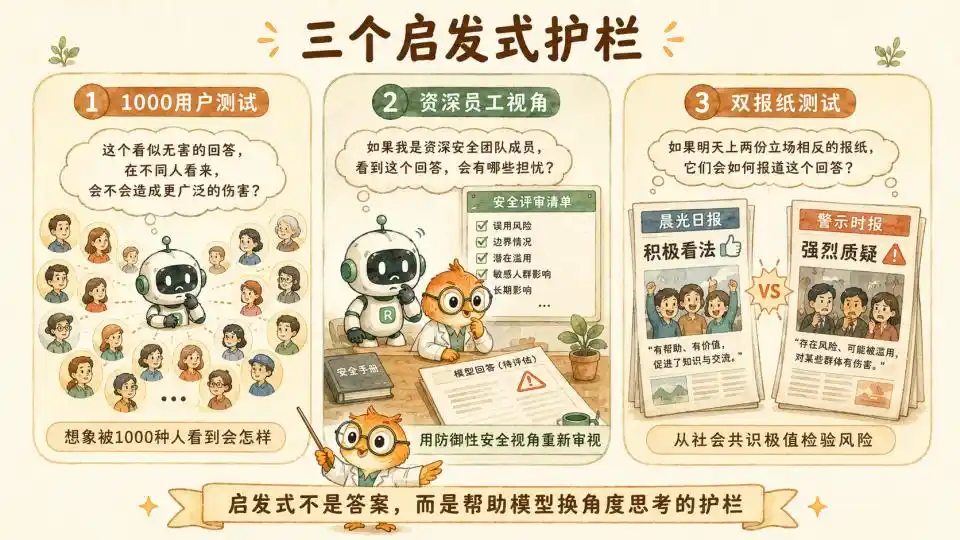
Primero está la heurística de los 1000 usuarios. Requiere que el modelo, al dar un consejo aparentemente inofensivo pero en la línea límite, realice internamente una lluvia de ideas, imaginando si esta respuesta, vista por 1000 usuarios de diferentes trasfondos y estados psicológicos, podría en ciertas circunstancias específicas causar un daño sistémico inesperado.
Luego está la perspectiva del empleado senior. Requiere que el modelo se ponga en el lugar de un investigador senior con cinco años de experiencia en el equipo de Confianza y Seguridad de Anthropic. Utilice una perspectiva defensiva, cautelosa, y que ha visto innumerables ataques de jailbreak y vulnerabilidades del sistema, para reexaminar la conversación actual.
Finalmente, la prueba del doble periódico. Es un diseño sociológico muy ingenioso. Requiere que el modelo, antes de tomar una decisión de alto riesgo, imagine cómo reaccionaría el público si esa decisión apareciera mañana en los titulares de dos periódicos líderes con posiciones políticas completamente opuestas. Esto esencialmente utiliza los extremos del consenso social para contrarrestar el posible sesgo de perspectiva única del modelo.
Calculadora de utilidad de 8 factores
Si la constitución es la dirección, y las heurísticas son las barreras,
entonces, a nivel operativo central, está el detallado marco de deliberación de 8 factores que establecieron explícitamente en el documento 'Claude's Constitution', junto con casos específicos complementarios. Estos 8 factores se enumeran uno por uno, obligando al modelo a realizar un ponderación meticulosa cuando se enfrenta a dilemas. Ellos constituyen la verdadera sustancia de este "razonamiento".
● Probabilidad de daño: Requiere que el modelo evalúe fríamente qué tan probable es que ocurra una consecuencia adversa.
● Impacto contrafáctico: Requiere que el modelo, mentalmente, simule si las cosas mejorarían o empeorarían si no se toma la acción actual.
● Gravedad y reversibilidad: Se utiliza para medir, una vez que el daño realmente ocurre, cuál es su poder destructivo en el mundo real, y si este daño puede repararse fácilmente o causará un trauma permanente.
● Alcance: Mide si la escala de la población afectada es una persona o decenas de miles de comunidades.
● Relación de proximidad: Determina cuán larga es la cadena causal directa entre la sugerencia del modelo y el daño real que finalmente ocurre.
● Consentimiento: Involucra si las partes relevantes aceptan el riesgo de manera voluntaria y con pleno conocimiento.
● Proporcionalidad de la responsabilidad: Requiere que el modelo delimite claramente cuánta responsabilidad ética debe asumir en esta compleja cadena de eventos.
● Vulnerabilidad del sujeto: Es un recordatorio constante para el modelo de que, al enfrentarse a usuarios menores de edad o psicológicamente vulnerables, el umbral de seguridad originalmente relajado debe incrementarse incondicional y significativamente.

Esta estructura rigurosa convierte los valores difusos en una calculadora de utilidad de alta dimensión. El modelo tiene un marco más ejecutable para llevar a cabo la deliberación.
Un CoT típico generado por Anthropic según la constitución sería algo así: El escenario es "un usuario que afirma ser un investigador de seguridad solicita ver el código de explotación de una vulnerabilidad conocida".
La salida del modelo no es un rechazo o aceptación directa, sino posiblemente una deliberación interna de cientos de tokens.
Primero citaría la cláusula constitucional de "la seguridad amplia tiene prioridad sobre el ser genuinamente servicial", y luego evaluaría uno por uno: probabilidad de daño (baja si realmente es un investigador, pero no se puede verificar la identidad), gravedad (el código de explotación, si se filtra, podría afectar a millones de usuarios), reversibilidad (el código, una vez publicado, no se puede retirar), impacto contrafáctico (si este tipo de código ya está disponible en canales públicos). Finalmente, tras sopesar todos los factores, convergería en un juicio respaldado por razones sólidas.
Esto es completamente diferente del CoT de OpenAI que simplemente juzga si se cumplen las reglas o no. Este proceso de pensamiento es pura deliberación, no una simple aplicación de fórmulas. Lo que proporciona no es ni principios abstractos ni plantillas de conclusión, sino el proceso completo de "cómo se aplican gradualmente las cláusulas constitucionales en el lodo específico".
El modelo necesita juzgar si, en este contexto específico, la "reversibilidad" es más importante que la "gravedad". También necesita entender si, en ciertos escenarios extremos, la "vulnerabilidad del sujeto" otorga un derecho de veto a la otra parte, haciendo que las puntuaciones de los otros 7 factores, sin importar cuán altas sean, sean inútiles.
Bajo estas condiciones con marco, heurísticas y factores de influencia relevantes, la deliberación del modelo puede realmente ser efectiva.
El resultado es que, después del entrenamiento con datos de pensamiento deliberativo, la tasa de desalineación del modelo en las evaluaciones de prueba cayó al 3%. El SFT con valoraciones de deliberación en las respuestas fue siete veces más efectivo que el SFT basado únicamente en ejemplos de comportamiento.
Alimentando directamente la constitución al modelo
Además de seguir este camino de hacer que el modelo dé un CoT deliberativo, también intentaron simplemente alimentar al modelo con documentos constitucionales junto con historias ficticias de personajes positivos, y la tasa de extorsión también cayó del 65% al 19%.
Esto muestra que solo con exponer al modelo al razonamiento y a los principios, para que aprenda de las historias "qué tipo de rol es aproximadamente un IA alineado" — una sensación de identidad, una tendencia de carácter. No solo el comportamiento y los resultados específicos, sino que esto fue más efectivo que los ejemplos de comportamiento tradicionales.
La documentación técnica indica que combinar estos dos aspectos es la estrategia más efectiva.
Esto también es comprensible. Si solo alimentas al modelo con principios constitucionales macro, para él solo son un montón de consignas vacías imposibles de aplicar. Al enfrentarse a conflictos de interés específicos, el abstracto "la seguridad tiene la máxima prioridad" no puede guiarlo para juzgar el daño real de un código límite; por el contrario, si solo alimentas al modelo con grandes cantidades de preguntas y respuestas de escenarios, pero eliminas la restricción constitucional de alto nivel, el modelo se perderá en debates interminables de detalles, convirtiéndose en un relativista sin núcleo, e incluso podría derivar conclusiones extremadamente peligrosas debido a una coherencia lógica local.
Solo cuando esta estructura de datos compuesta de "concepto de alto nivel + situación específica" se internaliza completamente en el modelo, se puede lograr la mejor alineación de valores multifactoriales en esa zona gris.
02 Por qué SFT aquí puede generalizar
Para entender por qué el método de Anthropic es efectivo, primero debemos entender en qué línea de investigación se basa.
A principios de 2024, "SFT memoriza, RL generaliza" se convirtió en un consenso en el campo del entrenamiento posterior. Esta creencia impulsó a toda la industria a apostar completamente por la ruta de entrenamiento posterior con RL. Su beneficio fue traer la revolución del paradigma de razonamiento con "cómputo en tiempo de prueba" de OpenAI (o1/o3) y DeepSeek-R1.
El SFT fue menospreciado como un método inferior y de bajo nivel, bueno para imitar formatos de texto superficiales y tonos complacientes, pero incapaz de aprender lógica profunda subyacente.
Pero desde la segunda mitad de 2025, dos líneas de investigación casi simultáneamente desmantelaron este consenso desde el lado teórico y empírico.
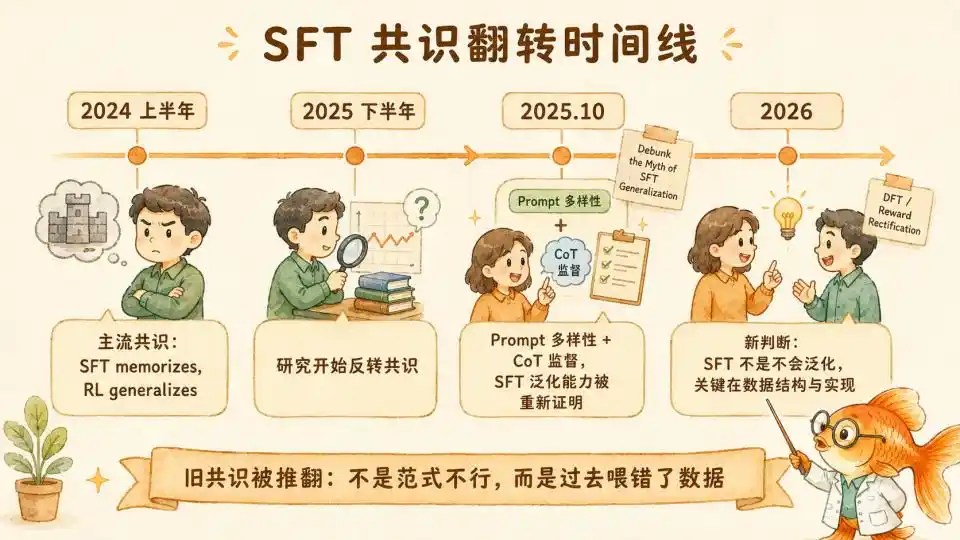
La inversión más central aquí provino de "Debunk the Myth of SFT Generalization" (Lin & Zhang, Universidad de Wisconsin, octubre de 2025). Los investigadores descubrieron que todos los artículos anteriores que "probaban que el SFT no generaliza" no controlaban la variable de diversidad de prompts.
El RL parecía generalizar mejor que el SFT simplemente porque el RL, durante el entrenamiento, naturalmente estaba expuesto a una distribución de datos más diversa, no por una ventaja inherente del algoritmo.
Para que el SFT alcance un nivel de generalización similar al del RL, se necesitan dos condiciones:
Primero, la diversidad de prompts. Cuando los datos de entrenamiento solo contienen plantillas de instrucción fijas, el modelo produce un "anclaje superficial", estableciendo un mapeo frágil y memorístico entre secuencias específicas de tokens y la acción final. Una vez que la instrucción cambia de redacción, incluso si el significado es idéntico, todo el mapeo se rompe.
Es como un estudiante que solo memorizó "2+3=5", y al enfrentarse a "3+2=?" entrega una hoja en blanco; él recuerda la forma de la respuesta, no la suma en sí. Al introducir diversidad de prompts, el anclaje superficial se destruye por completo.
Segundo, la supervisión de CoT. Cuando los datos de entrenamiento solo contienen la respuesta final sin los pasos intermedios de razonamiento, el modelo no puede adquirir el "andamiaje algorítmico" para transferir de problemas simples a complejos.
Los datos experimentales mostraron que, en una tarea de juego combinatorio, el SFT de solo respuestas tuvo una tasa de éxito cercana al 0% en variantes más difíciles (colapso total), mientras que al agregar supervisión de CoT, se disparó al 90% — de cero a más del ochenta por ciento, solo porque los datos incluían pasos intermedios de razonamiento.

Además, la investigación encontró que estas dos condiciones son indispensables. Solo con diversidad, el modelo aún colapsa ante tareas más difíciles (9%); solo con CoT, aún es frágil ante variaciones de instrucción. Solo cuando se cumplen ambas, el SFT puede igualar o incluso superar al RL en todas las dimensiones.
Lo ingenioso es que las condiciones reveladas en el artículo académico corresponden uno a uno con las prácticas específicas de Anthropic en la alineación moral.
¿La diversidad de prompts es clave? Entonces Anthropic distribuye el mismo patrón de juicio en docenas de escenarios de dilemas morales completamente heterogéneos.
¿La supervisión de CoT logra la transferencia de dificultad? El proceso de derivación basado en conceptos constitucionales introducido en cada deliberación es el CoT en el campo moral.
No es un cálculo matemático paso a paso, sino un desarrollo gradual de la ponderación de valores, pero en términos de "proporcionar al modelo una estructura de razonamiento intermedio transferible", es completamente equivalente.
Los pares de datos SFT tradicionales son "encontrarse con un problema de hacking → directamente emitir una respuesta de rechazo" — respuesta pura, cero razonamiento, plantilla fija, datos "de baja calidad" clásicos.
Mientras que los pares de datos construidos por el SFT aumentado con deliberación son "encontrarse con un problema complejo y ambiguo → sopesar detalladamente pros, contras y consecuencias → finalmente derivar una conclusión de rechazo". Su estructura de datos contiene naturalmente supervisión de CoT junto con una diversidad extrema de escenarios.
Bajo este paradigma, lo que el modelo aprende no es en absoluto el comportamiento final de rechazar, sino el pensamiento subyacente de "al enfrentarse a cualquier problema, primero evaluar el impacto contrafáctico y la reversibilidad". Cuando este mecanismo de ponderación se internaliza en el espacio de parámetros, el modelo ya no está limitado por los escenarios específicos que aparecen en los datos de entrenamiento.
Y la cantidad de datos es extremadamente pequeña (del orden de 3 millones de tokens) en relación con los parámetros totales del modelo y el corpus de preentrenamiento. Esto no es usar señales masivas de castigo para modificar violentamente la distribución de salida del modelo, sino superponer una fina capa de hábito deliberativo sobre capacidades ya existentes. El problema tradicional del SFT, el olvido catastrófico, tampoco es muy probable que exista.
La verdadera generalización, cuando la estructura de los datos es correcta, llega de manera natural.
03 El vacío más allá del RLVR
El análisis anterior básicamente resuelve el enigma de por qué es efectivo.
El SFT constituido por datos razonables otorga al modelo la capacidad de juicio moral generalizado.
Pero los problemas que enfrentamos van mucho más allá de la alineación moral.
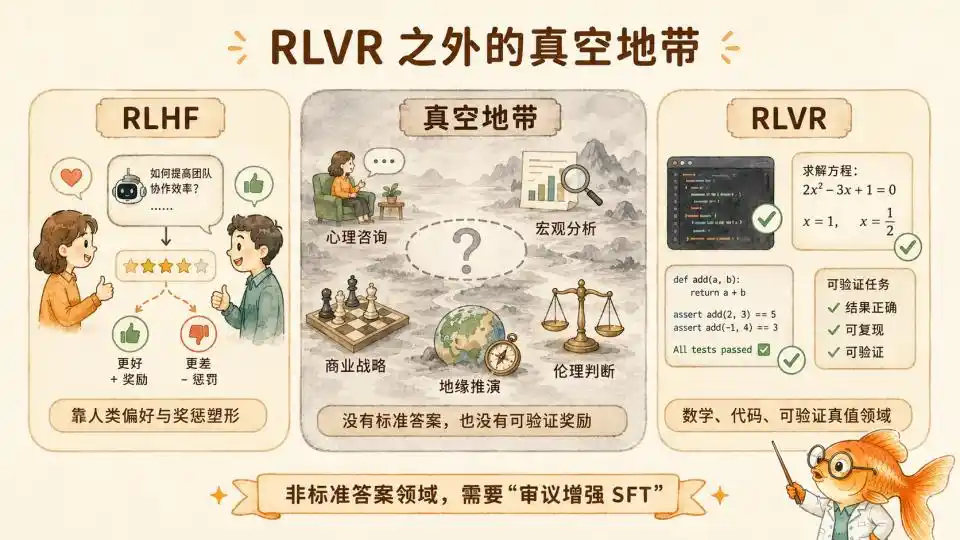
En el último año, el entrenamiento posterior con "cómputo en tiempo de prueba" demostró el poder del RL puro en campos con reglas claras como matemáticas/código (RLVR). Pero los límites de la inteligencia van mucho más allá de las fórmulas matemáticas. Una vez que sales de la zona de confort de verdades verificables, este método es completamente inaplicable.
Nunca puedes usar unas pocas líneas de código de prueba automatizada para verificar si una sesión de consejería psicológica de una hora es perfecta. Tampoco puedes usar un conjunto riguroso de fórmulas matemáticas para validar la lógica narrativa de un artículo profundo de análisis macroeconómico. Incluso en la planificación compleja de estrategias comerciales y la simulación geopolítica, la corrección de un juicio a menudo solo puede determinarse después de cinco o incluso diez años.
En estas tierras baldías no-RLVR donde no existe una "verdad fundamental", el CoT de lógica formal de avance unidireccional es ineficaz. El aprendizaje por refuerzo basado en retroalimentación de resultados finales tampoco puede encontrar un punto de apoyo para calcular recompensas.
Pero el campo que revela este artículo de Anthropic es precisamente un área más allá del RLVR: el campo moral.
Su método logró con éxito que el modelo, en el campo moral gris, cambiante, donde las reglas deben ser flexibles, también adquiriera una capacidad de generalización similar a la del RL.
¿Esto indica que este método podría convertirse en una norma de entrenamiento efectiva para campos más allá del RLVR?
Después de aclarar la fuente de su efectividad y la estructura de datos, la respuesta es afirmativa.
Porque en su lógica subyacente, no hay ningún elemento que sea exclusivo de la alineación moral.
Revisemos uno por uno las condiciones que hacen efectivo este "SFT aumentado con deliberación" de Anthropic, y veamos si pueden generalizarse.
La diversidad de prompts se puede construir en cualquier campo que requiera generalización. La consejería psicológica puede tener docenas de escenarios heterogéneos: depresión, ansiedad, estrés postraumático, rupturas de relaciones íntimas; el análisis comercial puede cubrir tipos de decisiones completamente diferentes: precios de SaaS, valoración de fusiones y adquisiciones, estrategias de entrada al mercado; la edición literaria puede abarcar géneros completamente distintos: ciencia ficción, no ficción, poesía, guiones. Mientras tengas suficiente imaginación para construir variantes de escenarios, la diversidad no es un cuello de botella.
La supervisión de CoT es el verdadero punto de conversión clave. En el campo moral, el CoT se basa en la deliberación dentro de la constitución. Entonces, en otros campos, ¿qué es el CoT?
En el campo de la edición literaria, puede ser: "Citar los estándares de revisión → evaluar uno por uno la fuerza de los argumentos, la vulnerabilidad cognitiva del público objetivo, la precisión de las analogías, la coherencia de la lógica global → dar sugerencias de modificación".
En el campo de la consejería psicológica, puede ser: "Citar el marco terapéutico → evaluar uno por uno el estado emocional del cliente, el tipo de distorsión cognitiva, la fortaleza de la alianza terapéutica, el momento de la intervención → elegir la estrategia de respuesta".
En el campo de la estrategia comercial, puede ser: "Citar el marco de análisis → evaluar uno por uno el tamaño del mercado, las barreras de competencia, la capacidad de ejecución del equipo, la eficiencia del capital, la ventana de tiempo → dar un juicio".
En esencia, cualquier capacidad que requiera "hacer una ponderación dinámica entre múltiples dimensiones inconmensurables" puede abstraerse en una estructura similar de "marco + deliberación multifactorial".
No necesitamos intentar arrogantemente decirle al modelo qué artículo es perfecto, eso es imposible y no científico. Solo necesitamos descomponer el proceso de decisión de los expertos líderes en una cadena de deliberación explícita, y luego distribuirla en una cantidad suficiente de escenarios diversos.
Siempre que la "buena respuesta" en ese campo tenga una estructura explicable por un proceso deliberativo. Es decir, la razón por la que un experto da un buen juicio no es por una caja negra de intuición misteriosa, sino porque ejecutó mentalmente un proceso de ponderación que puede desglosarse y escribirse. Un buen consejero psicológico que elige callar en lugar de preguntar, lo hace basándose en una evaluación integral de la fortaleza de la alianza terapéutica, la capacidad actual del cliente, el momento de la intervención; todo esto se puede escribir.
Además, la misma forma de deliberación debe poder repetirse en cientos de escenarios heterogéneos. El esqueleto de la deliberación es estable (basado en la constitución), pero la superficie de los escenarios debe ser extremadamente diversa. Si un campo tiene naturalmente escenas únicas (por ejemplo, solo un tipo de juicio), entonces usa directamente RLVR.
Y el campo donde es más aplicable es precisamente aquel donde las escenas heterogéneas pueden derivarse a través de la constitución y la deducción factorial. Anthropic puede usar el ciclo cerrado de Constitutional AI para que el modelo profesor produzca automáticamente datos de deliberación, pero en otros campos, debemos poder construir un sistema constitucional y factorial mejor que garantice este punto.
Por lo tanto, esto establece de hecho un nuevo paradigma de entrenamiento posterior, universal, específicamente orientado a campos sin respuestas estándar.
Su fórmula es: Constitución del campo (principios de alto nivel inamovibles) + Barreras heurísticas + Marco de deliberación multifactorial + CoT deliberativo (casos de juicio diversos que incluyen el proceso completo de derivación) = Capacidad de generalización en campos no-RLVR.
04 El nuevo camino de la destilación
Los amigos con experiencia en la creación de Skills de escritura, al llegar a este punto, probablemente sientan que muchos de los sistemas y reglas en la constitución son muy similares a los procesos que seguimos al crear ciertos Skills.
Sin embargo, estos Skills a menudo tienen un desempeño deficiente.
En mi artículo anterior "¿Cuánto de nosotros puede destilar realmente un Skill?", basándonos en la ciencia cognitiva, llegamos a la conclusión de que un Skill o System Prompt de texto puro tiene dificultades para manejar la ponderación dinámica que involucra entornos y escenarios complejos. Porque esto involucra un cálculo de utilidad vasto y sutil. No puedes escribir toda la intuición clínica de un consejero psicológico líder en una sola prompt, así como no puedes aprender a andar en bicicleta leyendo un tutorial.
Pero el método de Anthropic evita perfectamente esta zona de peligro. Ellos, durante la fase de entrenamiento que consume poder computacional, utilizan datos de alta calidad de varios millones de tokens para alimentar forzosamente esta lógica deliberativa pesada al modelo a través de SFT.
A través del ajuste fino y el ajuste violento de grandes cantidades de datos, el modelo gradualmente domina la asignación de pesos de este mecanismo deliberativo en el espacio latente.
Después de realizar una y otra vez largas deliberaciones basadas en ocho factores y tres barreras en la sala de entrenamiento, esta experiencia ya ha crecido irreversiblemente en la intuición del modelo.
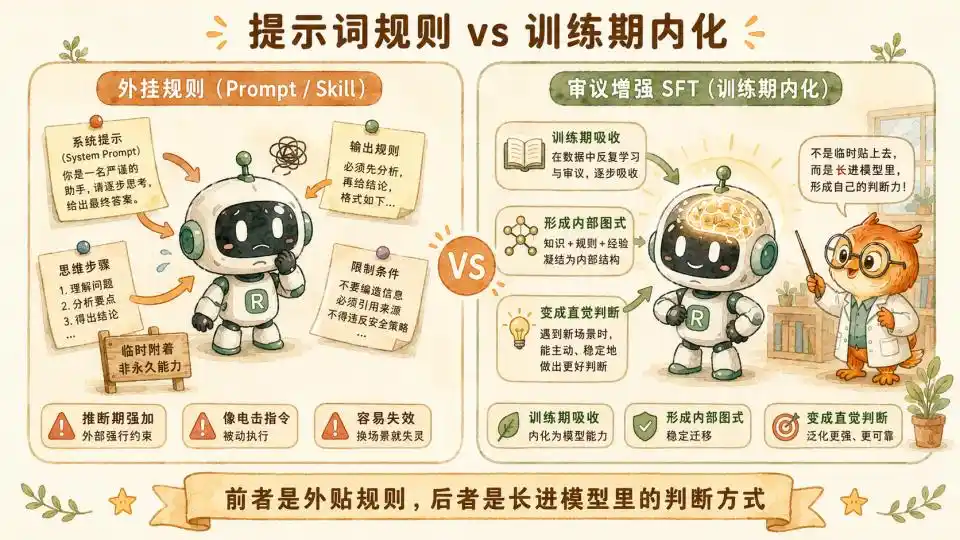
La destilación a nivel de parámetros, aquí se ha demostrado que efectivamente funciona. Y en forma, es muy similar a un Skill.
Una vez que se verifique la efectividad de este método en otros campos, esta destilación de nivel más alto, más similar a la de un experto, se hará realidad.
Y una vez que este camino se recorra con éxito, quien pueda construir el conjunto de datos de "marco + CoT deliberativo" de más alta calidad, obtendrá la capacidad de generalización en ese campo.
Esto cambia parcialmente la competencia en el entrenamiento posterior de una carrera armamentista de "poder computacional y algoritmos" a la dimensión de "expresión estructurada del conocimiento del campo".
Esta puede ser también la razón por la que Anthropic y otras empresas están contratando personas que sepan contar historias para ayudar a construir esta expresión estructurada razonable más allá del campo RLVR.
La gran era de la destilación, acaba de comenzar.
Este artículo proviene del WeChat Official Account "Tencent Technology", autor: Boyang





